Week 1 Part 1 - Transformers Architecture
These notes were developed using lectures/material/transcripts from the DeepLearning.AI & AWS - Generative AI with Large Language Models course
Notes
- Self-Attention - ability to learn the relevance and context of all the words in a sentence
- Attention weights are learned during training
- These layers reflect the importance of each word in that input sequence to all other words in the sequence
- Attention weights are learned during training
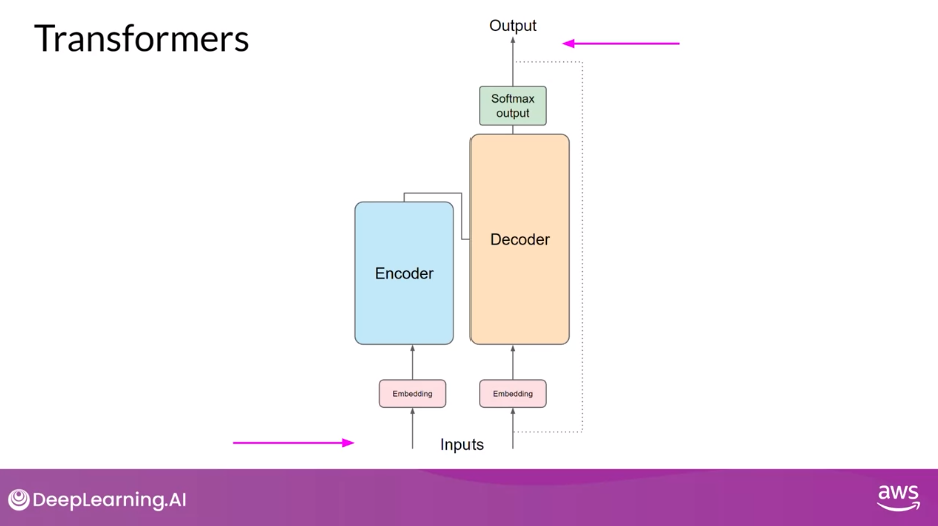
- Transformer Architecture: Encoder-Decoder
- Translation: sequence-to-sequence task
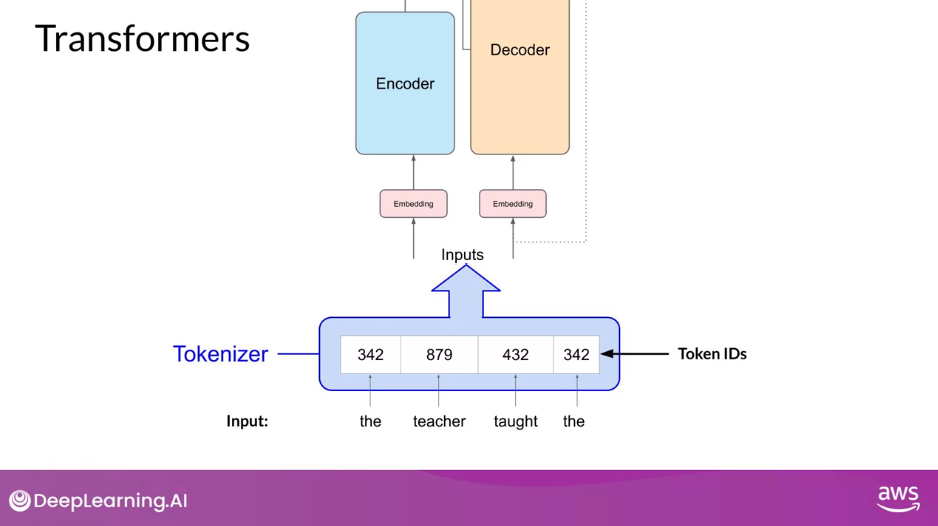
- Tokenizer - converts words into numbers, with each number representing a position in a dictionary of all the possible words that the model can work with
- Each token is mapped to a token ID
- Subword tokenization - gets the best of word-level tokenization and character-level tokenization
- Note: must use the same tokenizer when generating text
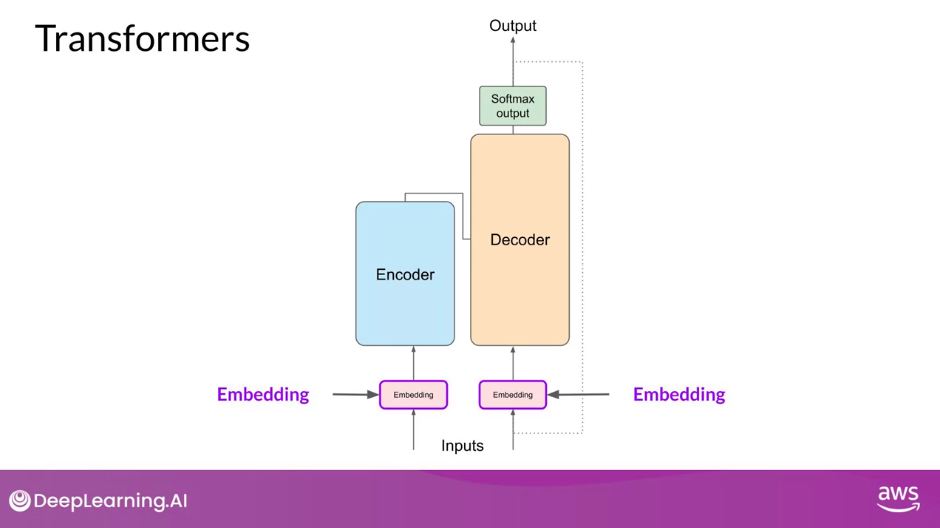
- Embedding
- Each token ID is mapped to a vector
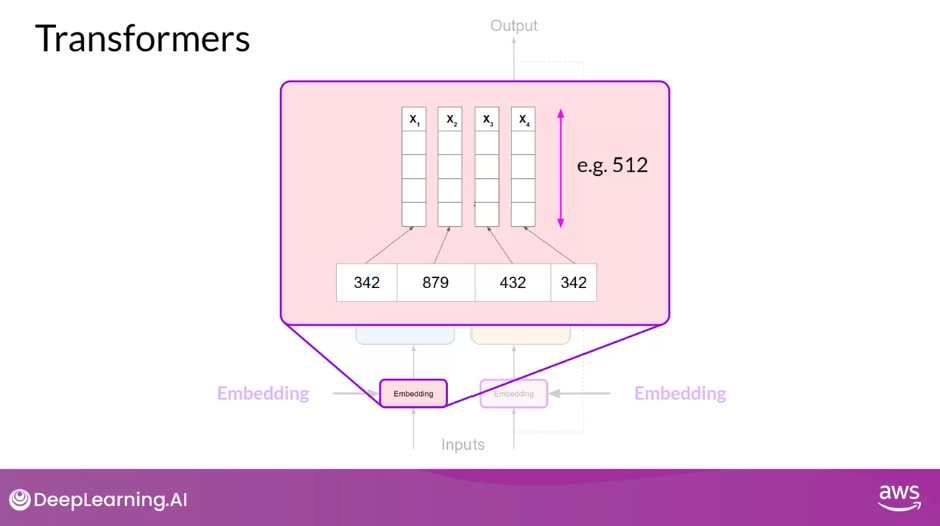
- Original transformer has embedding size of 512
- Weights are learned during training - these vectors learn to encode the meaning and context of individual tokens in the input sequence
- Positional Encoding
- Model processes each of the input tokens in parallel
- Adding positional encoding preserves the information about the word order
- Self-Attention Layer
- Analyzes the relationships between the tokens
- Attend to different parts of the input sequence to better capture the contextual dependencies between the words
- Weights are learned during training - reflect the importance of each word in that input sequence to all other words in the sequence
- Multi-Headed Attention Layer
- Multiple sets of self-attention weights or heads are learned in parallel independently of each other
- Fully Connected Feed-Forward Network
- Output of this layer is a vector of logits proportional to the probability score for each and every token in the tokenizer dictionary
- Softmax Layer
- Logits are normalized into a probability score for each word in the vocabulary
- The most likely predicted token will have the highest score
- Text Generation Strategies
Transformers Architecture
Self-Attention
- The power of the transformer architecture lies in its ability to learn the relevance and context of all of the words in a sentence
- Not just as you see here, to each word next to its neighbor, but to every other word in a sentence and to apply attention weights to those relationships so that the model learns the relevance of each word to each other words no matter where they are in the input
- These attention weights are learned during LLM training
- This is called self-attention and the ability to learn attention in this way across the whole input significantly approves the model’s ability to encode language

Simplified Diagram of the Transformer Architecture
- The transformer architecture is split into two distinct parts
- the encoder and
- the decoder
- These components work in conjunction with each other and they share a number of similarities
Tokenizer
- Before passing texts into the model to process, you must first tokenize the words
- This converts the words into numbers, with each number representing a position in a dictionary of all the possible words that the model can work with
- Multiple tokenization methods
- Word tokenization,
- Character-level tokenization,
- Subword tokenization
- What’s important is that once you’ve selected a tokenizer to train the model, you must use the same tokenizer when you generate text
Embedding
- Now that your input is represented as numbers, you can pass it to the embedding layer
- This layer is a trainable vector embedding space, a high-dimensional space where each token is represented as a vector and occupies a unique location within that space
- Each token ID in the vocabulary is matched to a multi-dimensional vector, and the intuition is that these vectors learn to encode the meaning and context of individual tokens in the input sequence
- Embedding vector spaces have been used in natural language processing for some time, previous generation language algorithms like word2vec use this concept
- Looking back at the sample sequence, you can see that in this simple case, each word has been matched to a token ID, and each token is mapped into a vector
- In the original transformer paper, the vector size was actually 512
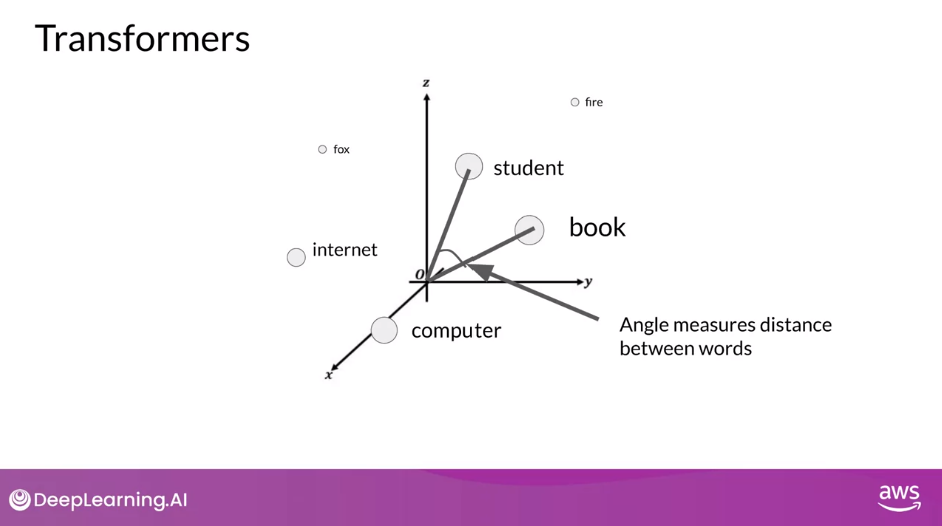
Visualization: Embedding in 3D
- For simplicity, if you imagine a vector size of just three, you could plot the words into a three-dimensional space and see the relationships between those words.
- You can see now how you can relate words that are located close to each other in the embedding space, and how you can calculate the distance between the words as an angle, which gives the model the ability to mathematically understand language
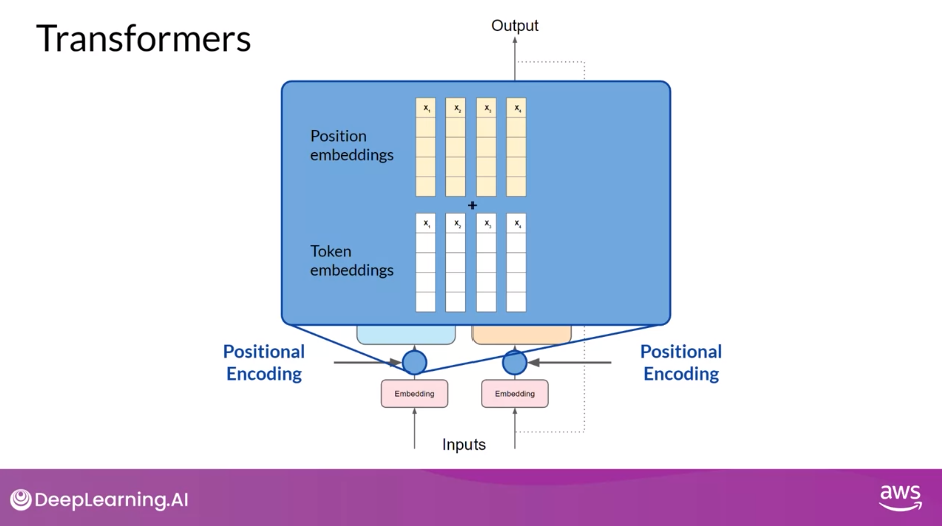
Positional Encoding
- As you add the token vectors into the base of the encoder or the decoder, you also add positional encoding
- The model processes each of the input tokens in parallel
- So by adding the positional encoding, you preserve the information about the word order and don’t lose the relevance of the position of the word in the sentence.
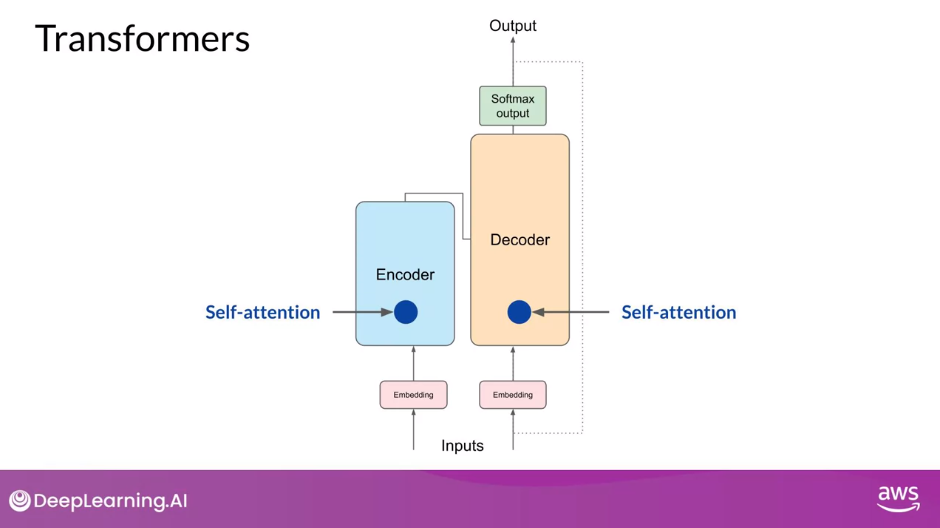
Self-Attention Layer
- Once you’ve summed the input tokens and the positional encodings, you pass the resulting vectors to the self-attention layer
- The model analyzes the relationships between the tokens in your input sequence.
- As you saw earlier, this allows the model to attend to different parts of the input sequence to better capture the contextual dependencies between the words.
- The self-attention weights that are learned during training and stored in these layers reflect the importance of each word in that input sequence to all other words in the sequence.
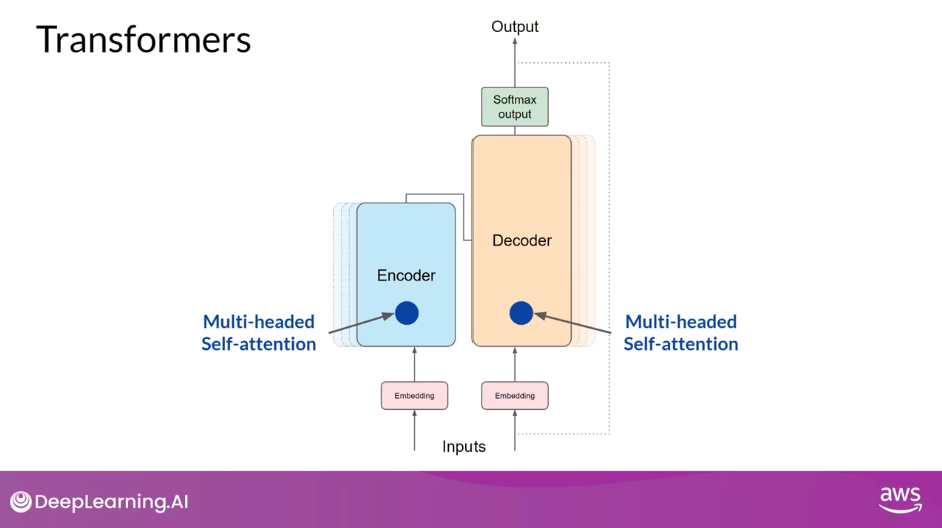
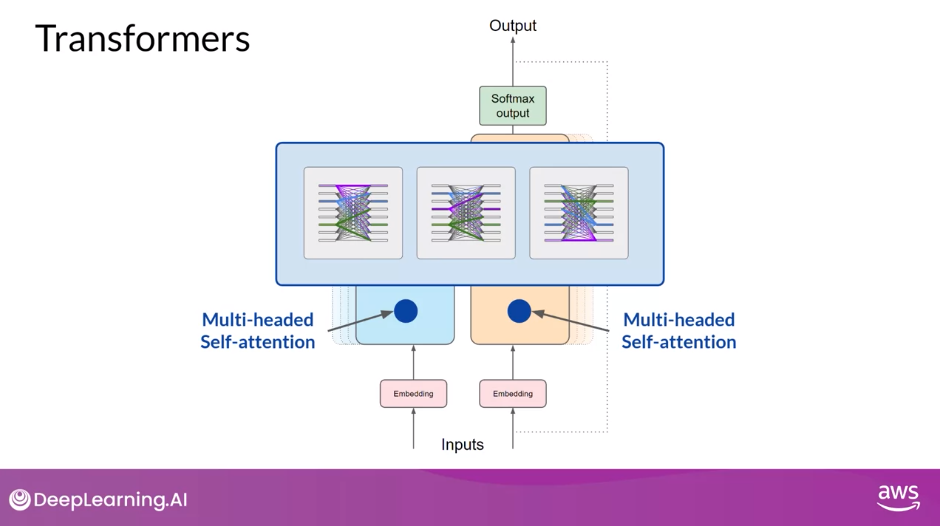
Multi-Headed Attention Layer
- But this does not happen just once, the transformer architecture actually has multi-headed self-attention. This means that multiple sets of self-attention weights or heads are learned in parallel independently of each other. The number of attention heads included in the attention layer varies from model to model, but numbers in the range of 12-100 are common. The intuition here is that each self-attention head will learn a different aspect of language.
- For example, one head may see the relationship between the people entities in our sentence.
- Whilst another head may focus on the activity of the sentence.
- Whilst yet another head may focus on some other properties such as if the words rhyme.
- Note: you don’t dictate ahead of time what aspects of language the attention heads will learn.
- The weights of each head are randomly initialized and given sufficient training data and time, each will learn different aspects of language.
- While some attention maps are easy to interpret, like the examples discussed here, others may not be.
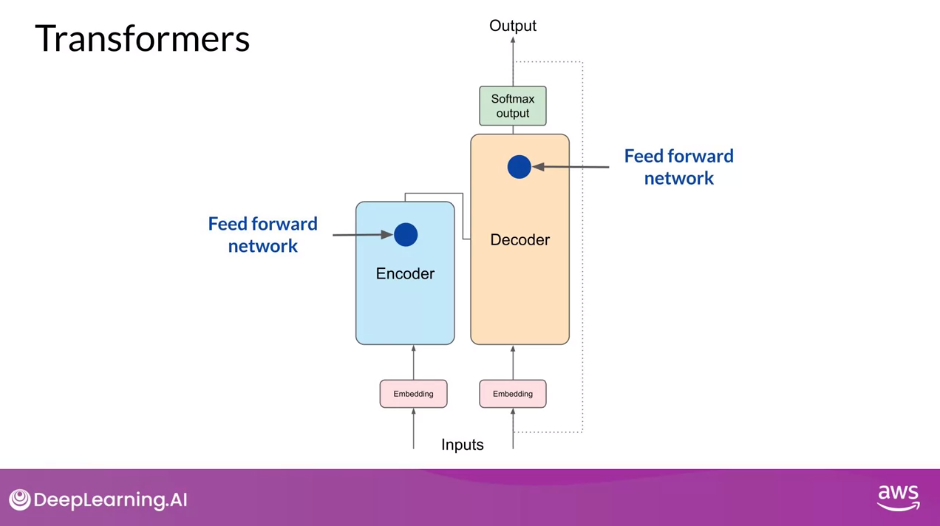
Fully-Connected Feed-Forward Network
- Now that all of the attention weights have been applied to your input data, the output is processed through a fully-connected feed-forward network.
- The output of this layer is a vector of logits proportional to the probability score for each and every token in the tokenizer dictionary
Softmax Layer
- Pass these logits to a final softmax layer, where they are normalized into a probability score for each word. This output includes a probability for every single word in the vocabulary, so there’s likely to be thousands of scores here. One single token will have a score higher than the rest. This is the most likely predicted token.
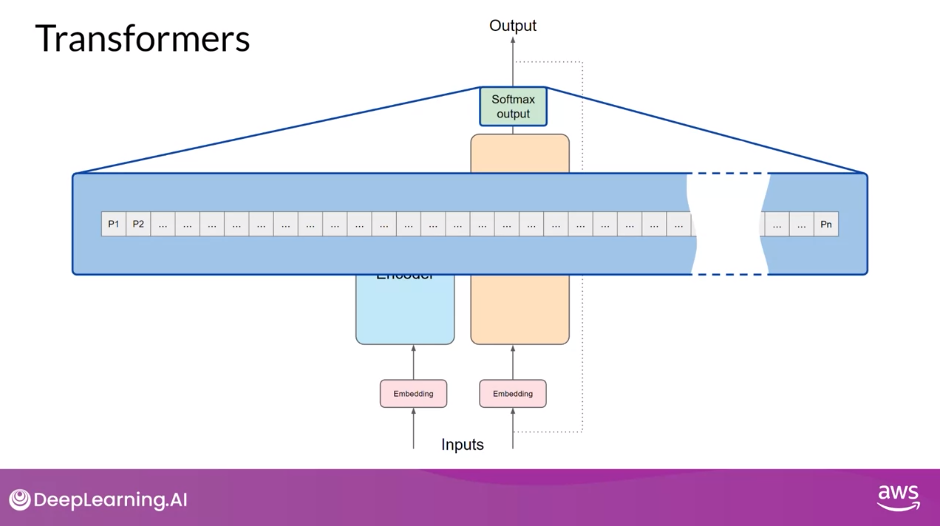
There are a number of methods that you can use to vary the final selection from this vector of probabilities (Text Generation Strategies)