Week 1 Part 1 - Introduction to LLMs and the Generative AI Project Lifecycle
These notes were developed using lectures/material/transcripts from the DeepLearning.AI & AWS - Generative AI with Large Language Models course
Notes
- Generative AI & LLMs
- Gen AI - subset of machine learning
- Models learn statistical patterns in massive datasets of content
- Gen AI - subset of machine learning
- LLM Use Cases and Tasks
- Augmenting LLMs by connecting them to external data sources or using them to invoke external APIs
- Provide the model with information it doesn’t know from its pre-training
- Text Generation Before Transformers
- Transformers Architecture
- Generating Text with Transformers
- How the Overall Prediction Process Works
- Encoder-Decoder Architecture
- Encoder - encodes input sequences into a deep representation of the structure and meaning of the input
- Decoder - working from input token triggers, uses the encoder’s contextual understanding to generate new tokens, does this in a loop until a stop condition is reached
- Variants
- Encoder-only - BERT
- Encoder-Decoder - BART
- Decoder-only - GPT, BLOOM, LLaMA
- Reading: Transformers: Attention is All You Need (2017)
- https://arxiv.org/abs/1706.03762
- Transformer model - entirely attention-based
- Self-Attention - compute representations of input sequences, capture long-term dependencies and parallelize computation effectively
- Encoder-Decoder Layers
- Two Sublayers
- Multi-Head Self-Attention - allows the model to attend to different parts of the input sequence
- Feed-Forward Neural Network - applies a point-wise fully connected layer to each position separately and identically
- Two Sublayers
- Residual Connections and Layer Normalization - facilitate training and prevent overfitting
- Positional Encoding - encodes the position of each token in the input sequence, capture the order of the sequence
- Prompting and Prompt Engineering
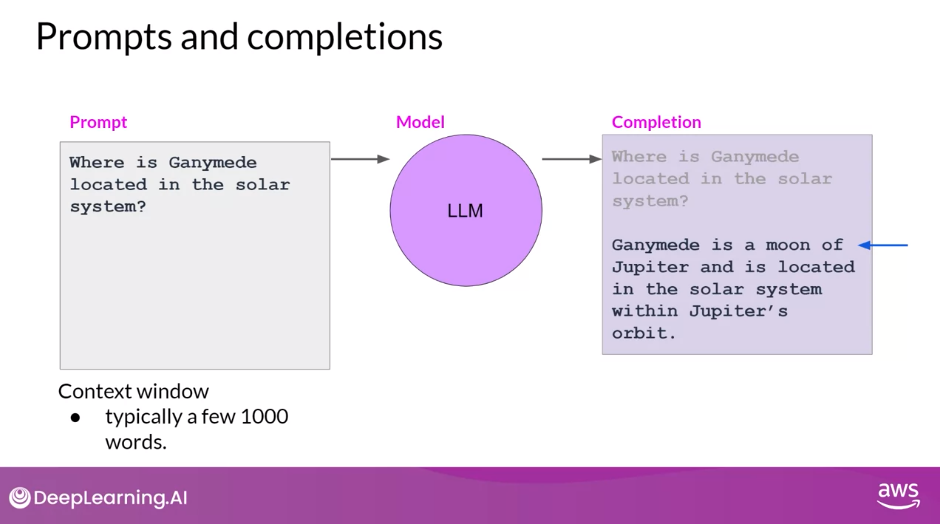
- Prompt - text that you feed into the model
- Inference - act of generating text
- Completion - the output text
- Context Window - full amount of text or the memory that is available to use for the prompt
- Prompt Engineering - work to develop and improve the prompt
- In-Context Learning - engineer your prompts to encourage the model to learn by examples
- Zero Shot Inference
- One Shot Inference
- Few Shot Inference
- Generative Configuration - Inference Parameters
- max_new_tokens - limit the number of tokens that the model will generate
- Greedy Decoding - the word/token with the highest probability is selected
- Random Sampling - select a token using a random-weighted strategy across the probabilities of all tokens
- do_sample=True - to disable greedy decoding and enable random sampling
- top_k sampling - choose from only the k tokens with the highest probability
- specify the number of tokens to randomly choose from
- top_p sampling - limit the random sampling to the predictions whose combined probabilities do not exceed p
- specify the total probability that you want the model to choose from
- temperature - control the randomness of the model output
- the higher the temperature, the higher the randomness, and the lower the temperature, the lower the randomness
- How it works?
- influences the shape of the probability distribution that the model calculates for the next token
- temperature value is a scaling factor that’s applied within the final softmax layer of the model that impacts the shape of the probability distribution of the next token
- Generative AI Project Lifecycle
- Scope - define the scope as accurately and narrowly as you can
- Select - train your own model or work with an existing model
- Adapt and Align - assess its performance and carry out additional training if needed
- Prompt Engineering
- Fine-tuning
- Full Fine-tuning
- Parameter Efficient Fine-tuning (PEFT)
- Reinforcement Learning from Human Feedback (RLHF)
- Application Integration - optimize your model for deployment and consider any additional infrastructure that your application will require to work well
- Lab 1 - Prompt Engineering
- Task: Dialogue Summarization
- Prompt Template
- Zero Shot Inference
- One Shot Inference
- Few Shot Inference
- Text Generation Strategies
- do_sample=True
- temperature
Generative AI & LLMs
- Generative AI is a subset of traditional machine learning. And the machine learning models that underpin generative AI have learned these abilities by finding statistical patterns in massive datasets of content that was originally generated by humans
- Large language models have been trained on trillions of words (tokens) over many weeks and months, and with large amounts of compute power
- These foundation models (base models), as we call them, with billions of parameters, exhibit emergent properties beyond language alone, and researchers are unlocking their ability to break down complex tasks, reason, and problem solve
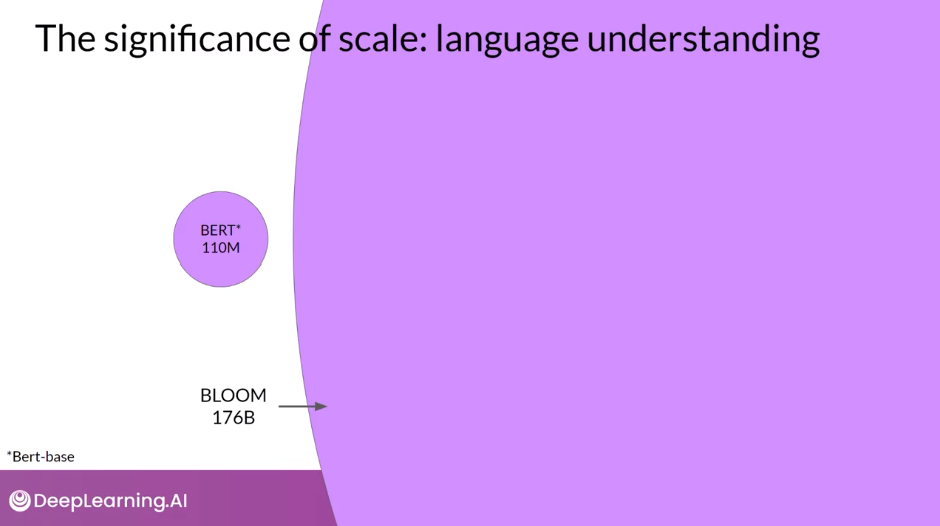
- Here are a collection of foundation models, sometimes called base models, and their relative size in terms of their parameters. You’ll cover these parameters in a little more detail later on, but for now, think of them as the model’s memory.
- And the more parameters a model has, the more memory, and as it turns out, the more sophisticated the tasks it can perform
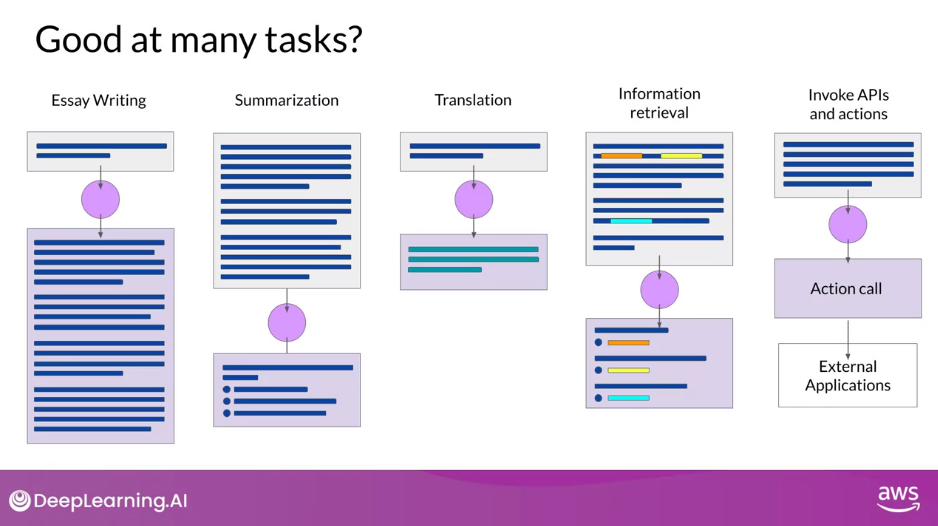
LLM Use Cases and Tasks
- An area of active development is augmenting LLMs by connecting them to external data sources or using them to invoke external APIs. You can use this ability to provide the model with information it doesn’t know from its pre-training and to enable your model to power interactions with the real-world
- Developers have discovered that as the scale of foundation models grows from hundreds of millions of parameters to billions, even hundreds of billions, the subjective understanding of language that a model possesses also increases. This language understanding stored within the parameters of the model is what processes, reasons, and ultimately solves the tasks you give it, but it’s also true that smaller models can be fine tuned to perform well on specific focused tasks
Text Generation Before Transformers
- RNNs, powerful for their time, were limited by the amount of compute and memory needed to perform well at generative tasks
- As you scale the RNN implementation to be able to see more of the preceding words in the text, you have to significantly scale the resources that the model uses
- The problem here is that language is complex. In many languages, one word can have multiple meanings

Transformers Architecture
Generating Text with Transformers
How the Overall Prediction Process Works from End to End
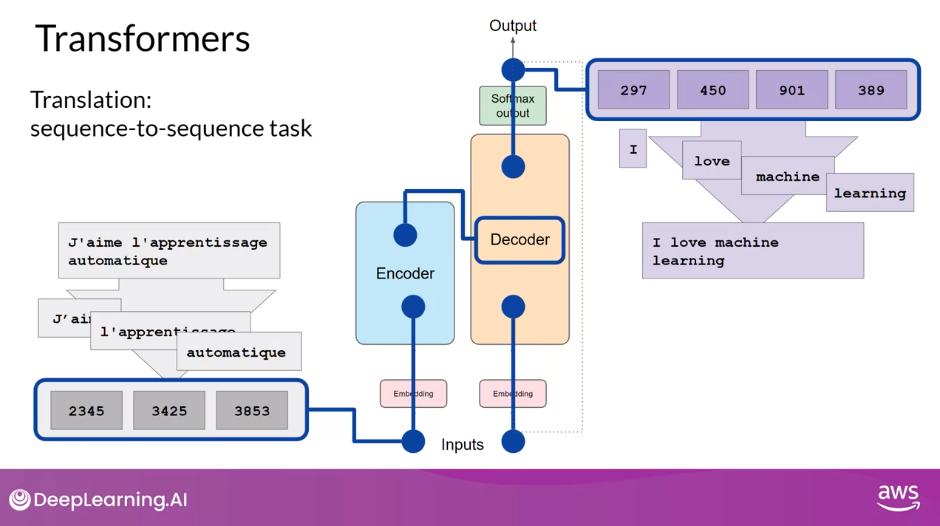
- Look at a translation task or a sequence-to-sequence task, which incidentally was the original objective of the transformer architecture designers
- Translate the French phrase [FOREIGN] into English
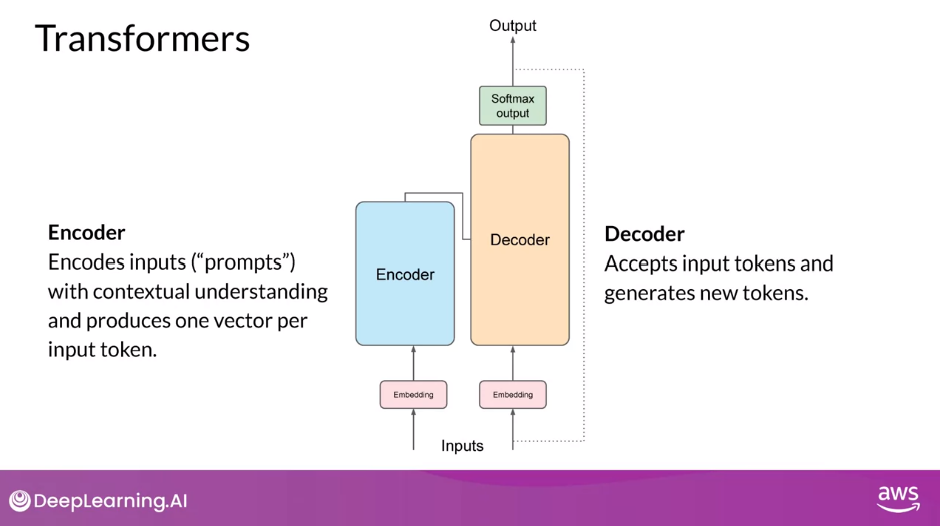
Encoder
- First, you’ll tokenize the input words using this same tokenizer that was used to train the network. These tokens are then added into the input on the encoder side of the network, passed through the embedding layer, and then fed into the multi-headed attention layers. The outputs of the multi-headed attention layers are fed through a feed-forward network to the output of the encoder. At this point, the data that leaves the encoder is a deep representation of the structure and meaning of the input sequence.
Decoder
- This representation is inserted into the middle of the decoder to influence the decoder’s self-attention mechanisms.
- Next, a start of sequence token is added to the input of the decoder. This triggers the decoder to predict the next token, which it does based on the contextual understanding that it’s being provided from the encoder. The output of the decoder’s self-attention layers gets passed through the decoder feed-forward network and through a final softmax output layer. At this point, we have our first token. You’ll continue this loop, passing the output token back to the input to trigger the generation of the next token, until the model predicts an end-of-sequence token. At this point, the final sequence of tokens can be detokenized into words, and you have your output. In this case, I love machine learning
Text Generation Strategies
- There are multiple ways in which you can use the output from the softmax layer to predict the next token. These can influence how creative your generated text is
Summary
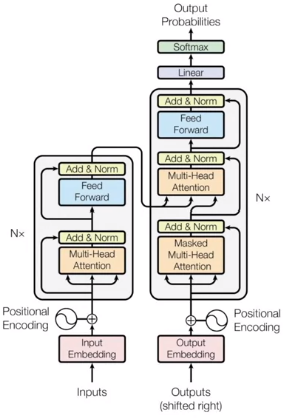
- The complete transformer architecture consists of an encoder and decoder components
- The encoder encodes input sequences into a deep representation of the structure and meaning of the input
- The decoder, working from input token triggers, uses the encoder’s contextual understanding to generate new tokens. It does this in a loop until some stop condition has been reached
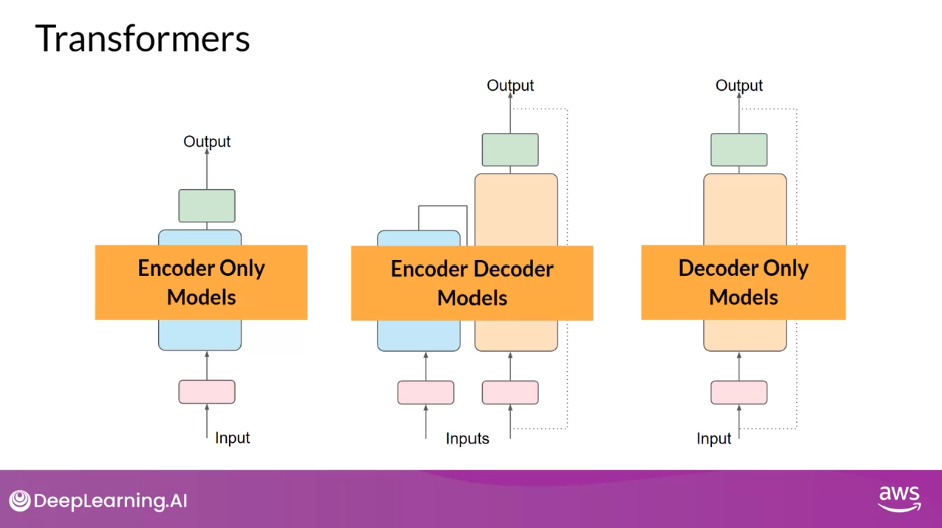
Variants
- While the translation example you explored here used both the encoder and decoder parts of the transformer, you can split these components apart for variations of the architecture.
- Encoder-only models also work as sequence-to-sequence models, but without further modification, the input sequence and the output sequence or the same length. Their use is less common these days, but by adding additional layers to the architecture, you can train encoder-only models to perform classification tasks such as sentiment analysis, BERT is an example of an encoder-only model.
- Encoder-decoder models, as you’ve seen, perform well on sequence-to-sequence tasks such as translation, where the input sequence and the output sequence can be different lengths. You can also scale and train this type of model to perform general text generation tasks. Examples of encoder-decoder models include BART as opposed to BERT and T5, the model that you’ll use in the labs in this course.
- Finally, decoder-only models are some of the most commonly used today. Again, as they have scaled, their capabilities have grown. These models can now generalize to most tasks. Popular decoder-only models include the GPT family of models, BLOOM, Jurassic, LLaMA, and many more.
- You’ll be interacting with transformer models through natural language, creating prompts using written words, not code. You don’t need to understand all of the details of the underlying architecture to do this. This is called Prompt Engineering
Reading: Transformers: Attention is All You Need (2017)
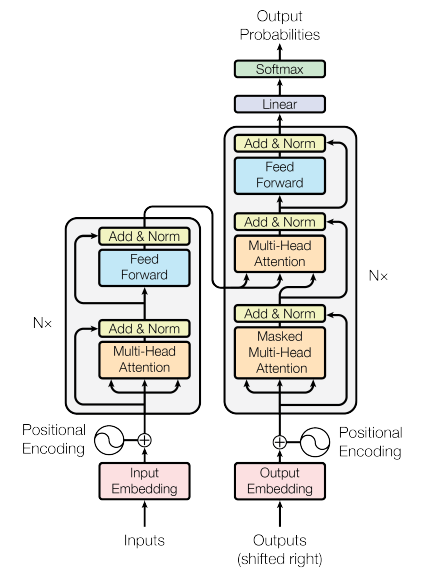
“Attention is All You Need” is a research paper published in 2017 by Google researchers, which introduced the Transformer model, a novel architecture that revolutionized the field of natural language processing (NLP) and became the basis for the LLMs we now know - such as GPT, PaLM and others. The paper proposes a neural network architecture that replaces traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) with an entirely attention-based mechanism.
The Transformer model uses self-attention to compute representations of input sequences, which allows it to capture long-term dependencies and parallelize computation effectively. The authors demonstrate that their model achieves state-of-the-art performance on several machine translation tasks and outperform previous models that rely on RNNs or CNNs.
The Transformer architecture consists of an encoder and a decoder, each of which is composed of several layers. Each layer consists of two sub-layers: a multi-head self-attention mechanism and a feed-forward neural network. The multi-head self-attention mechanism allows the model to attend to different parts of the input sequence, while the feed-forward network applies a point-wise fully connected layer to each position separately and identically.
The Transformer model also uses residual connections and layer normalization to facilitate training and prevent overfitting. In addition, the authors introduce a positional encoding scheme that encodes the position of each token in the input sequence, enabling the model to capture the order of the sequence without the need for recurrent or convolutional operations.
You can read the Transformers paper here.
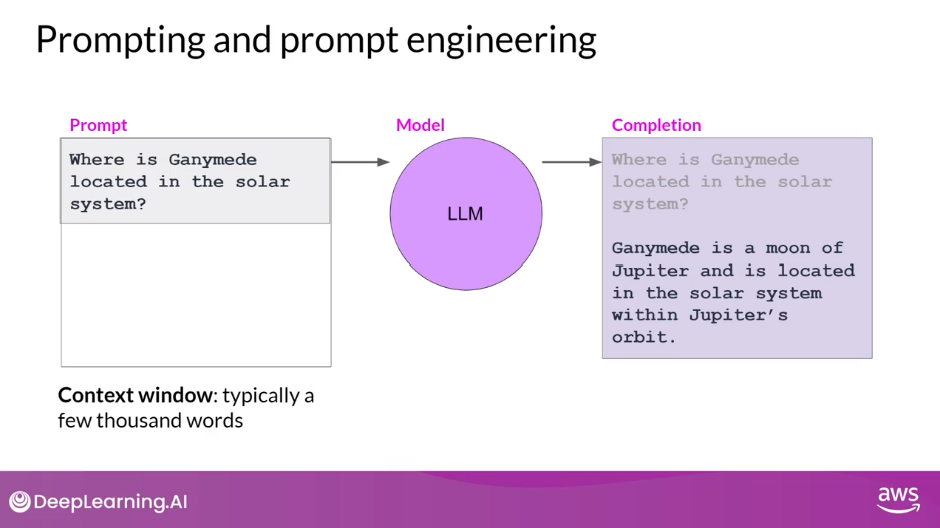
Prompting and Prompt Engineering
- Terminology
- text that you feed into the model is called the prompt
- the act of generating text is known as inference
- the output text is known as the completion
- The full amount of text or the memory that is available to use for the prompt is called the context window
- This work to develop and improve the prompt is known as prompt engineering
- Providing examples inside the context window is called in-context learning
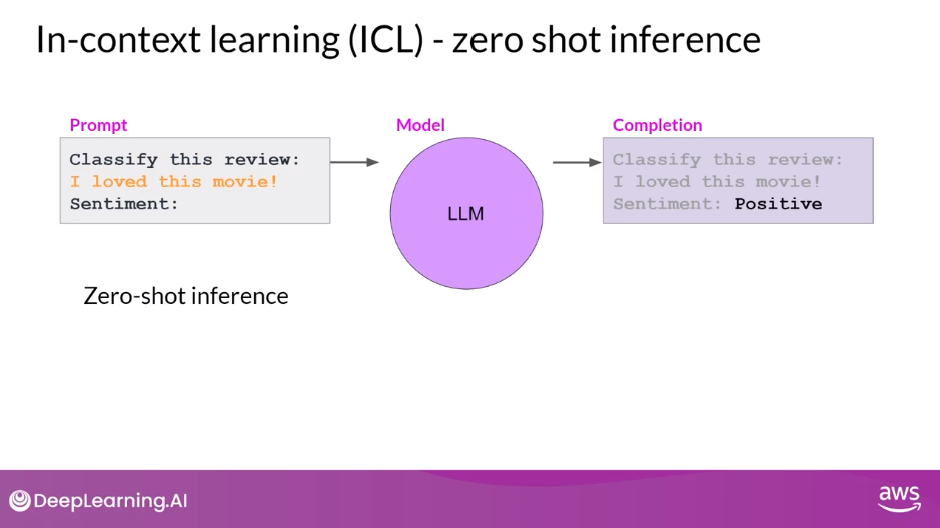
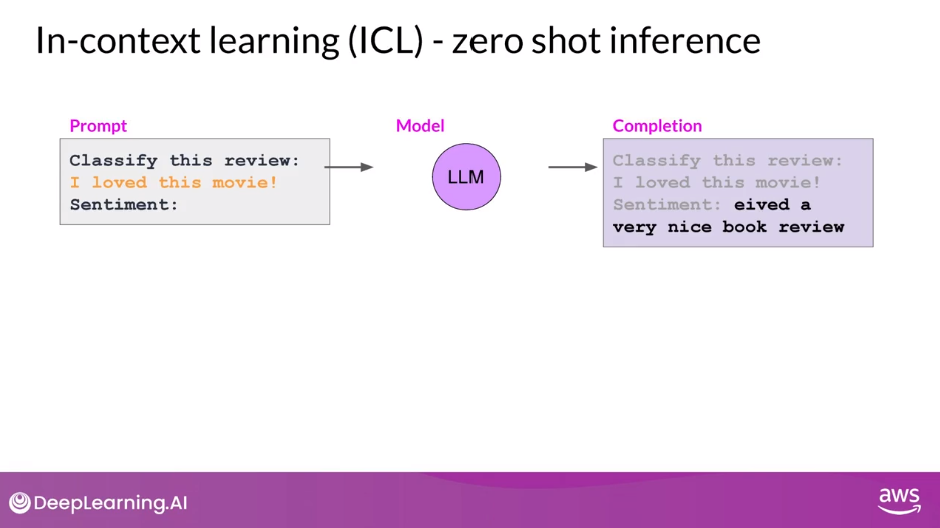
Zero Shot Inference
- Providing examples inside the context window is called in-context learning
- The largest of the LLMs are surprisingly good at this, grasping the task to be completed and returning a good answer
- Smaller models, on the other hand, can struggle with this
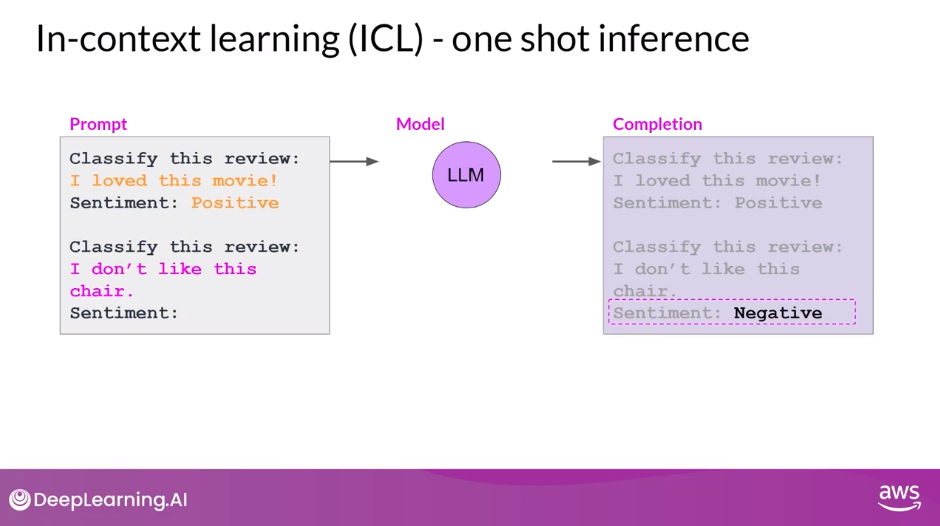
One Shot Inference
- Providing an example within the prompt can improve performance
- The inclusion of a single example is known as one-shot inference, in contrast to the zero-shot prompt you supplied earlier
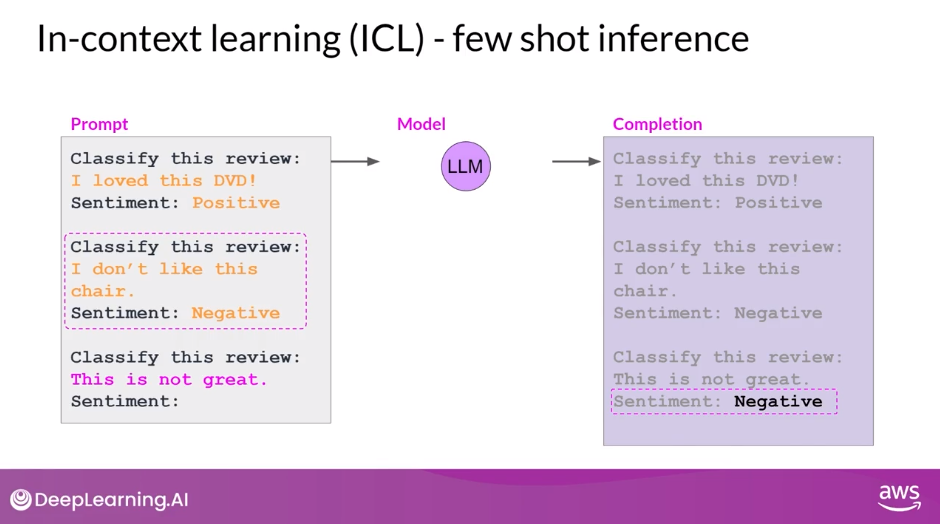
Few Shot Inference
- can extend the idea of giving a single example to include multiple examples. This is known as few-shot inference
- including a mix of examples with different output classes can help the model to understand what it needs to do
Summary of In-Context Learning (ICL)
- To recap, you can engineer your prompts to encourage the model to learn by examples. While the largest models are good at zero-shot inference with no examples, smaller models can benefit from one-shot or few-shot inference that include examples of the desired behavior.
- But remember the context window because you have a limit on the amount of in-context learning that you can pass into the model. Generally, if you find that your model isn’t performing well when, say, including five or six examples, you should try fine-tuning your model instead. Fine-tuning performs additional training on the model using new data to make it more capable of the task you want it to perform

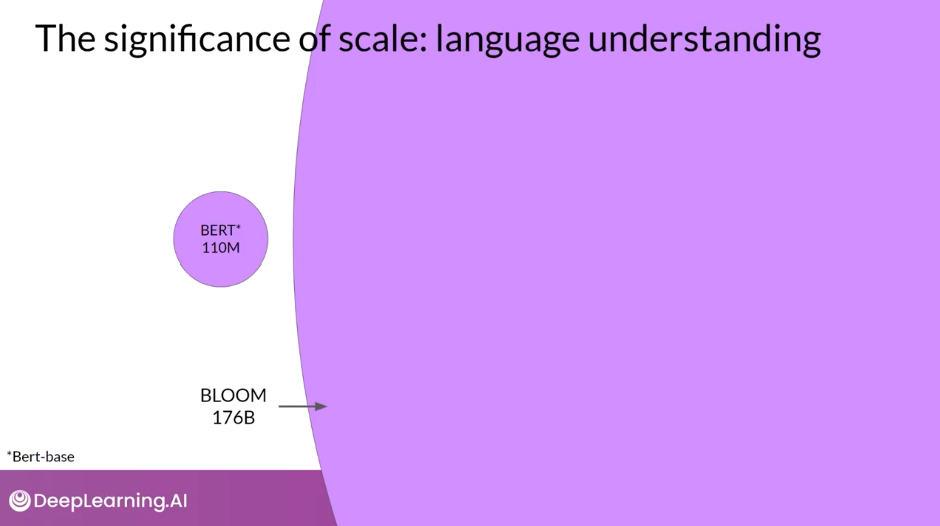
The Significance of Scale: Language Understanding
- As larger and larger models have been trained, it’s become clear that the ability of models to perform multiple tasks and how well they perform those tasks depends strongly on the scale of the model. As you heard earlier in the lesson, models with more parameters are able to capture more understanding of language. The largest models are surprisingly good at zero-shot inference and are able to infer and successfully complete many tasks that they were not specifically trained to perform. In contrast, smaller models are generally only good at a small number of tasks. Typically, those that are similar to the task that they were trained on. You may have to try out a few models to find the right one for your use case.
- Once you’ve found the model that is working for you, there are a few settings that you can experiment with to influence the structure and style of the completions that the model generates.
Question: Which in-context learning method involves creating an initial prompt that states the task to be completed and includes a single example question with answer followed by a second question to be answered by the LLM?
One shot
One shot inference involves providing an example question with answer followed by a second question to be answered by the LLM. Few shot inference provides multiple example prompts and answers while zero shot provides only one prompt to be answered by the LLM.
Generative Configuration
- Examine some of the methods and associated configuration parameters that you can use to influence the way that the model makes the final decision about next-word generation
- Each model exposes a set of configuration parameters that can influence the model’s output during inference
- Note that these are different than the training parameters which are learned during training time. Instead, these configuration parameters are invoked at inference time and give you control over things like the maximum number of tokens in the completion, and how creative the output is
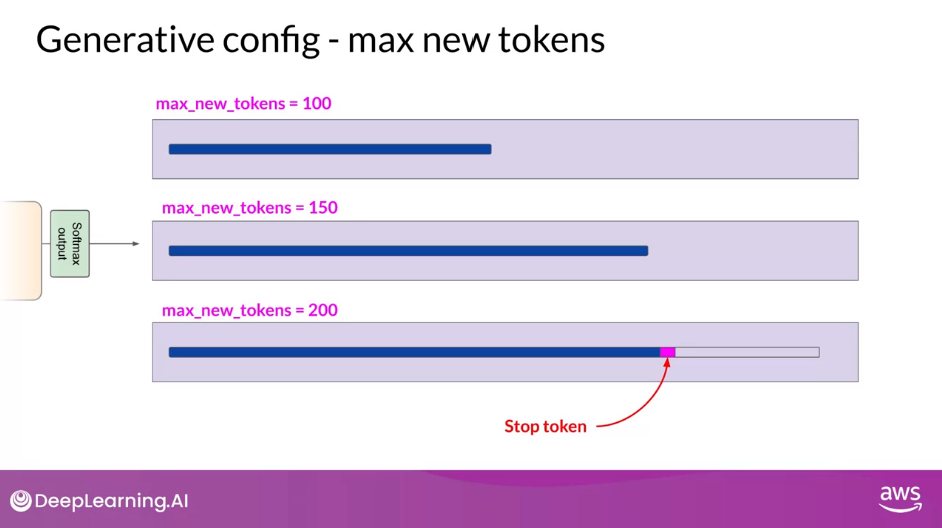
max_new_tokens
- max_new tokens - use it to limit the number of tokens that the model will generate. You can think of this as putting a cap on the number of times the model will go through the selection process

- Note how the length of the completion in the example for 200 is shorter. This is because another stop condition was reached, such as the model predicting and end of sequence token. Remember it’s max new tokens, not a hard number of new tokens generated
- The output from the transformer’s softmax layer is a probability distribution across the entire dictionary of words that the model uses. Here you can see a selection of words and their probability score next to them. Although we are only showing four words here, imagine that this is a list that carries on to the complete dictionary.
Greedy Decoding
- Simplest form of next-word prediction, where the model will always choose the word with the highest probability
- can work very well for short generation but is susceptible to repeated words or repeated sequences of words
- If you want to generate text that’s more natural, more creative and avoids repeating words, you need to use some other controls
Random Sampling
- Easiest way to introduce some variability, model chooses an output word at random using the probability distribution to weight the selection
- For example, in the illustration, the word banana has a probability score of 0.02. With random sampling, this equates to a 2% chance that this word will be selected. By using this sampling technique, we reduce the likelihood that words will be repeated. However, depending on the setting, there is a possibility that the output may be too creative, producing words that cause the generation to wander off into topics or words that just don’t make sense.
- Note that in some implementations, you may need to disable greedy and enable random sampling explicitly.
- For example, the Hugging Face transformers implementation that we use in the lab requires that we set do_sample=True

- Let’s explore top k and top p sampling techniques to help limit the random sampling and increase the chance that the output will be sensible
- Two Settings, top p and top k are sampling techniques that we can use to help limit the random sampling and increase the chance that the output will be sensible
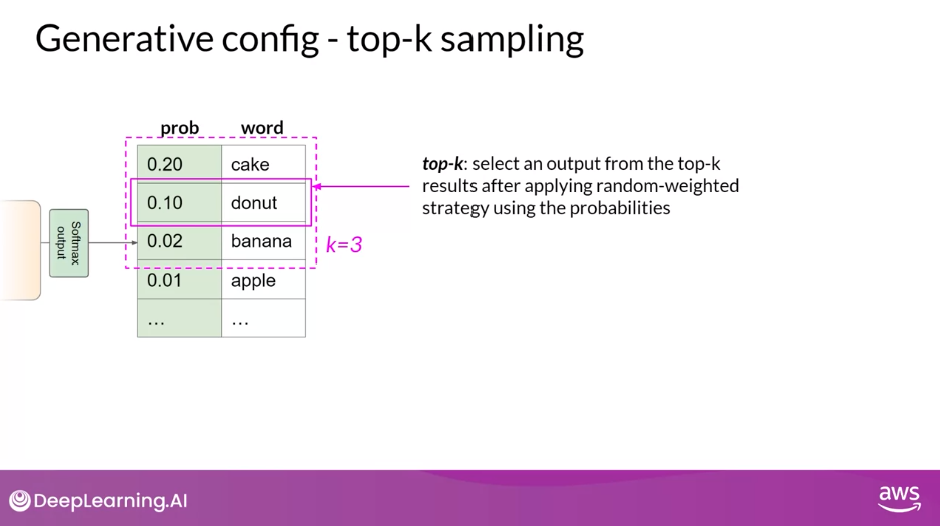
top_k sampling
- To limit the options while still allowing some variability, you can specify a top k value which instructs the model to choose from only the k tokens with the highest probability.
- In this example here, k is set to three, so you’re restricting the model to choose from these three options. The model then selects from these options using the probability weighting and in this case, it chooses donut as the next word. This method can help the model have some randomness while preventing the selection of highly improbable completion words. This in turn makes your text generation more likely to sound reasonable and to make sense
top_p sampling
- Alternatively, you can use the top p setting to limit the random sampling to the predictions whose combined probabilities do not exceed p.
- For example, if you set p to equal 0.3, the options are cake and donut since their probabilities of 0.2 and 0.1 add up to 0.3. The model then uses the random probability weighting method to choose from these tokens.

With top k, you specify the number of tokens to randomly choose from, and
With top p, you specify the total probability that you want the model to choose from.
temperature
- One more parameter that you can use to control the randomness of the model output is known as temperature. This parameter influences the shape of the probability distribution that the model calculates for the next token. Broadly speaking, the higher the temperature, the higher the randomness, and the lower the temperature, the lower the randomness. The temperature value is a scaling factor that’s applied within the final softmax layer of the model that impacts the shape of the probability distribution of the next token. In contrast to the top k and top p parameters, changing the temperature actually alters the predictions that the model will make.
- If you choose a low value of temperature, say less than one, the resulting probability distribution from the softmax layer is more strongly peaked with the probability being concentrated in a smaller number of words. You can see this here in the blue bars beside the table, which show a probability bar chart turned on its side. Most of the probability here is concentrated on the word cake. The model will select from this distribution using random sampling and the resulting text will be less random and will more closely follow the most likely word sequences that the model learned during training.
- If instead you set the temperature to a higher value, say, greater than one, then the model will calculate a broader flatter probability distribution for the next token. Notice that in contrast to the blue bars, the probability is more evenly spread across the tokens. This leads the model to generate text with a higher degree of randomness and more variability in the output compared to a cool temperature setting. This can help you generate text that sounds more creative. If you leave the temperature value equal to one, this will leave the softmax function as default and the unaltered probability distribution will be used.

Question: Which configuration parameter for inference can be adjusted to either increase or decrease randomness within the model output layer?
- Temperature is used to affect the randomness of the output of the softmax layer. A lower temperature results in reduced variability while a higher temperature results in increased randomness of the output.
Summary up till this point
- examined the types of tasks that LLMs are capable of performing
- learned about transformers, the model architecture that powers these amazing tools
- explored how to get the best possible performance out of these models using prompt engineering
- experiment with different inference configuration parameters
In the next video, you’ll start building on this foundational knowledge by thinking through the steps required to develop and launch an LLM-powered application.
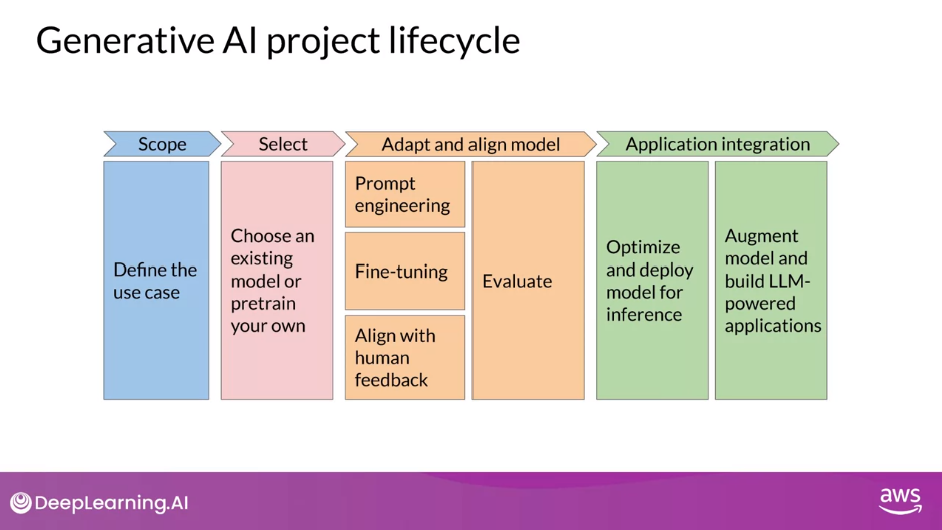
Generative AI Project Lifecycle
Scope
- The most important step in any project is to define the scope as accurately and narrowly as you can. As you’ve seen in this course so far, LLMs are capable of carrying out many tasks, but their abilities depend strongly on the size and architecture of the model. You should think about what function the LLM will have in your specific application.
Select
- Once you’re happy, and you’ve scoped your model requirements enough to begin development. Your first decision will be whether to train your own model from scratch or work with an existing base model. In general, you’ll start with an existing model, although there are some cases where you may find it necessary to train a model from scratch. You’ll learn more about the considerations behind this decision later this week, as well as some rules of thumb to help you estimate the feasibility of training your own model.
Adapt and Align
- With your model in hand, the next step is to assess its performance and carry out additional training if needed for your application.
- As you saw earlier this week, prompt engineering can sometimes be enough to get your model to perform well, so you’ll likely start by trying in-context learning, using examples suited to your task and use case. There are still cases, however, where the model may not perform as well as you need, even with one or a few short inference
- In that case, you can try fine-tuning your model. This supervised learning process will be covered in detail in Week 2, and you’ll get a chance to try fine tuning a model yourself in the Week 2 lab. As models become more capable, it’s becoming increasingly important to ensure that they behave well and in a way that is aligned with human preferences in deployment.
- In Week 3, you’ll learn about an additional fine-tuning technique called Reinforcement Learning from Human Feedback (RLHF), which can help to make sure that your model behaves well. An important aspect of all of these techniques is evaluation. Next week, you will explore some metrics and benchmarks that can be used to determine how well your model is performing or how well aligned it is to your preferences. Note that this adapt and aligned stage of app development can be highly iterative. You may start by trying prompt engineering and evaluating the outputs, then using fine tuning to improve performance and then revisiting and evaluating prompt engineering one more time to get the performance that you need.
Application Integration
- Finally, when you’ve got a model that is meeting your performance needs and is well aligned, you can deploy it into your infrastructure and integrate it with your application.
- At this stage, an important step is to optimize your model for deployment. This can ensure that you’re making the best use of your compute resources and providing the best possible experience for the users of your application.
- The last but very important step is to consider any additional infrastructure that your application will require to work well. There are some fundamental limitations of LLMs that can be difficult to overcome through training alone like their tendency to invent information when they don’t know an answer, or their limited ability to carry out complex reasoning and mathematics. In the last part of this course, you’ll learn some powerful techniques that you can use to overcome these limitations.
Scope
- The most important step in any project is to define the scope as accurately and narrowly as you can. As you’ve seen in this course so far, LLMs are capable of carrying out many tasks, but their abilities depend strongly on the size and architecture of the model. You should think about what function the LLM will have in your specific application. Do you need the model to be able to carry out many different tasks, including long-form text generation or with a high degree of capability, or is the task much more specific like named entity recognition so that your model only needs to be good at one thing. As you’ll see in the rest of the course, getting really specific about what you need your model to do can save you time and perhaps more importantly, compute cost.
Introduction to AWS Labs
- SageMaker Studio - a Jupyter based IDE that we’ll be doing all of our notebooks in today
Lab 1 Walkthrough - Mainly Going through Prompt Engineering
- Dataset: Dialogsum
- Model: Flan-T5 Base
- AutoModelForSeq2SeqLM
- Tokenizer - text to tokens
- The tokenizer’s job is to convert raw text into numbers. Those numbers point to a set of vectors or the embeddings as they’re often called, that are then used in mathematical operations like our deep learning, back-propagation, our linear algebra, all that fun stuff
- In-context Learning
- Zero Shot Inference - somewhat ok
- One Shot Inference - slightly better
- Few Shot Inference - in this case 3 full examples
- Doesn’t do much better than one shot inference
- Typically, in my experience, above five or six shots, so full prompt and then completions, you really don’t gain much after that. Either the model can do it or it can’t do it and going about five or six.
- Generative Configuration Parameters for Inference
- do_sample=True
- In some cases, for example, by raising the temperature up above, towards one or even closer to two, you will get very creative type of responses.
- temperature
- If you lower it down I believe 0.1 is the minimum for the hugging face implementation anyway, of this generation config class here that’s used when you actually generate. If you go down to 0.1, that will actually make the response more conservative and will oftentimes give you the same response over and over.
- If you go higher, I believe actually 2.0 is the highest. If you try to 2.0, that will start to give you some very wild responses.
- do_sample=True
Lab 1 - Generative AI Use Case: Summarize Dialogue
In this lab, you will do the dialogue summarization task using generative AI. You will explore
- how the input text affects the output of the model, and
- perform prompt engineering to direct it towards the task you need.
- By comparing zero shot, one shot, and few shot inferences, you will take the first step towards prompt engineering and see how it can enhance the generative output of Large Language Models.