Week 2 Part 2 - Parameter Efficient Fine-tuning
These notes were developed using lectures/material/transcripts from the DeepLearning.AI & AWS - Generative AI with Large Language Models course
Notes
- Full Fine-tuning - every model weight is updated during supervised learning
- Requires memory not just to store the model, but various other parameters that are required during the training process
- Weights
- Optimizer States
- Gradients
- Forward Activations
- Temporary Memory used
- Can lead to Catastrophic Forgetting
- Results in a new version of the model for every task you train on, thus can create an expensive storage problem if you’re fine-tuning for multiple tasks
- Requires memory not just to store the model, but various other parameters that are required during the training process
- Parameter Efficient Fine-tuning (PEFT) - only update a small subset of the model parameters
- Freezes most (if not all) of the original model weights and focus on fine-tuning a subset of (existing or additional) model parameters
- The number of trained parameters is much smaller than the number of parameters in the original LLM
- In some cases, just 15-20% of the original LLM weights
- The number of trained parameters is much smaller than the number of parameters in the original LLM
- More robust against Catastrophic Forgetting
- PEFT Saves Space and is Flexible
- Train only a small number of weights, which results in a much smaller footprint overall (MB, GB)
- New parameters are combined with the original LLM weights for inference
- The PEFT weights are trained for each task and can be easily swapped out for inference, allowing efficient adaptation of the original model to multiple tasks
- PEFT Trade-offs
- Parameter Efficiency
- Training Speed
- Inference Costs
- Model Performance
- Memory Efficiency
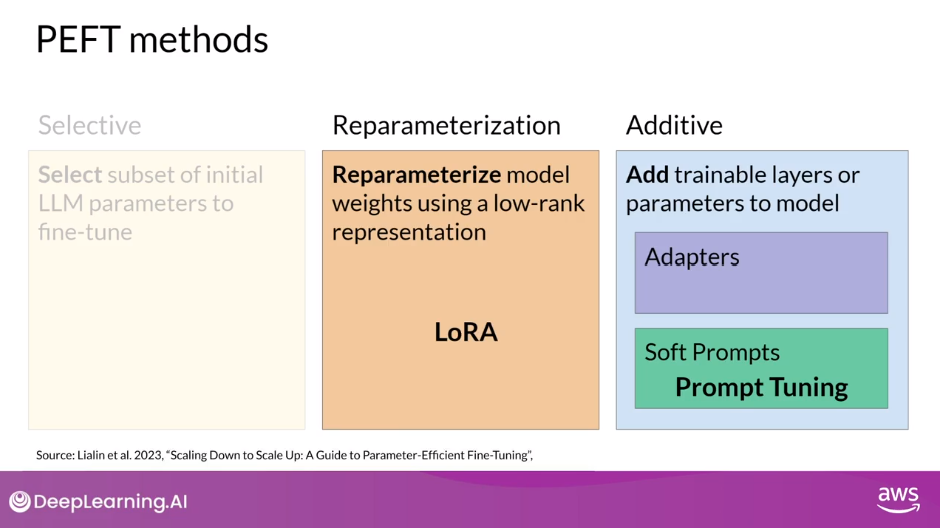
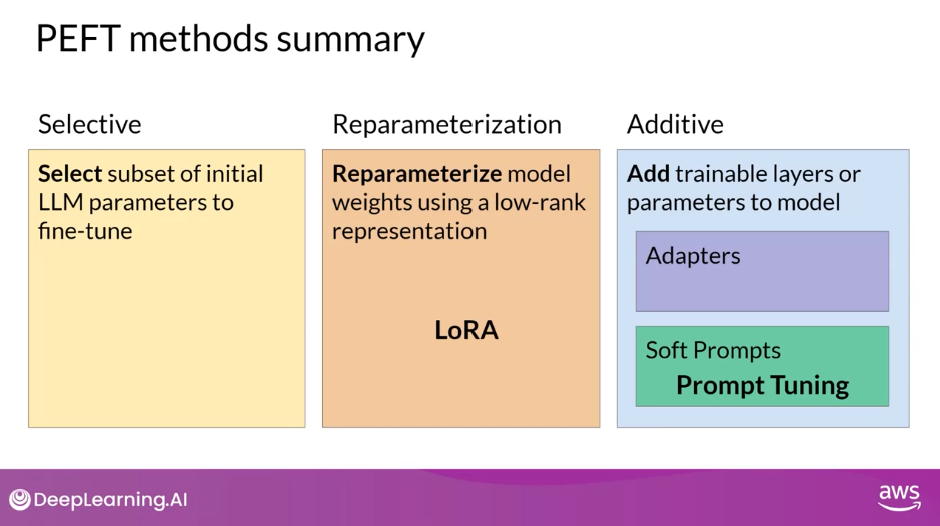
- Three Main Classes of PEFT Methods
- Selective - fine-tune only a subset of the original LLM parameters
- Reparameterization - work with the original LLM parameters, but reduce the number of parameters to train by creating new low rank transformations of the original network weights
- LoRA
- Additive - keep all of the LLM weights frozen and introduce new trainable components
- Adapters
- Soft Prompts - Prompt Tuning
- Freezes most (if not all) of the original model weights and focus on fine-tuning a subset of (existing or additional) model parameters
- PEFT Techniques 1: LoRA (Low Rank Adaptation of LLMs) - a strategy that reduces the number of parameters to be trained during fine-tuning by freezing all of the original model parameters and then injecting a pair of rank decomposition matrices alongside the original weights
- Training
- Freeze most of the original LLM weights
- Inject 2 Rank Decomposition Matrices (Rank r is small simension, typically 4, 8, …, 64)
- Train the weights of the smaller matrices
- Inference
- Matrix multiple the low rank matrices
- Add to original weights
- Latency - little to no impact as the model has the same number of parameters as the original
- Apply LoRA to the Self-Attention layers since most of the parameters of LLMs are in these layers
- Though it can also be applied to other layers as well like FFN layers
- Can often perform LoRA with a single GPU and avoid the need for a distributed cluster of GPUs
- Train on Different Tasks
- Train different rank decomposition matrices for different tasks
- Update weights before inference
- The memory required to store these LoRA matrices is very small, therefore can use LoRA to train for many tasks
- Choosing the LoRA Rank (r)
- The smaller the rank, the smaller the number of trainable parameters, the bigger the savings on compute
- Ranks in the range of 4-32 can provide you with a good trade-off between reducing trainable parameters and preserving performance
- Can combine with Quantization techniques to further reduce memory footprint: QLoRA
- Training
- PEFT Techniques 2: Soft Prompts
- Trainable tokens are added to the prompt and the model weights are left frozen
- Lab 2 - Fine-tune a Generative AI Model For Dialogue Summarization
- Model: flan-t5-base
- Task: Dialogue Summarization
- Metrics: ROUGE
- Comparison of model performance
- Original model
- Fully Fine-tuned model
- PEFT model
Parameter Efficient Fine-Tuning
- Training LLMs is computationally intensive
- Full fine-tuning requires memory not just to store the model, but various other parameters that are required during the training process.
- Even if your computer can hold the model weights, which are now on the order of hundreds of gigabytes for the largest models, you must also be able to allocate memory for optimizer states, gradients, forward activations, and temporary memory throughout the training process.
- These additional components can be many times larger than the model and can quickly become too large to handle on consumer hardware

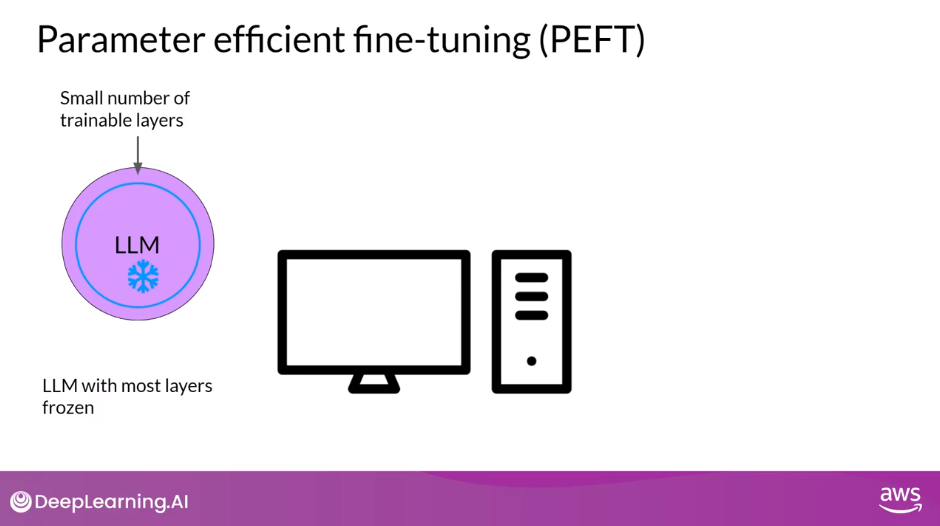
- In contrast to full fine-tuning where every model weight is updated during supervised learning, Parameter Efficient Fine-tuning (PEFT) methods only update a small subset of parameters.
- Some path techniques freeze most of the model weights and focus on fine-tuning a subset of existing model parameters, for example, particular layers or components
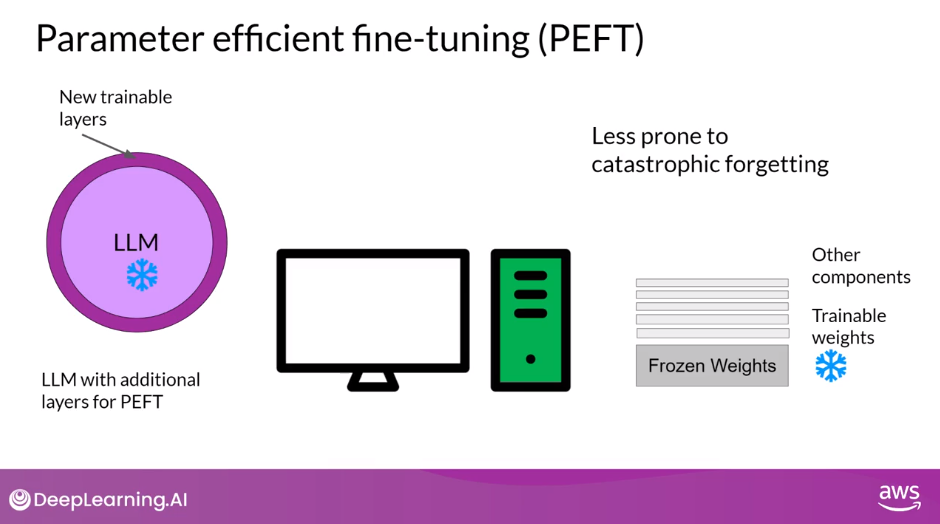
- Other techniques don’t touch the original model weights at all, and instead add a small number of new parameters or layers and fine-tune only the new components.
- With PEFT, most if not all of the LLM weights are kept frozen.
- As a result, the number of trained parameters is much smaller than the number of parameters in the original LLM.
- In some cases, just 15-20% of the original LLM weights.
- This makes the memory requirements for training much more manageable. In fact, PEFT can often be performed on a single GPU.
- And because the original LLM is only slightly modified or left unchanged, PEFT is less prone to the Catastrophic Forgetting problems of full fine-tuning
Full Fine-tuning Creates Full Copy of Original LLM Per Task
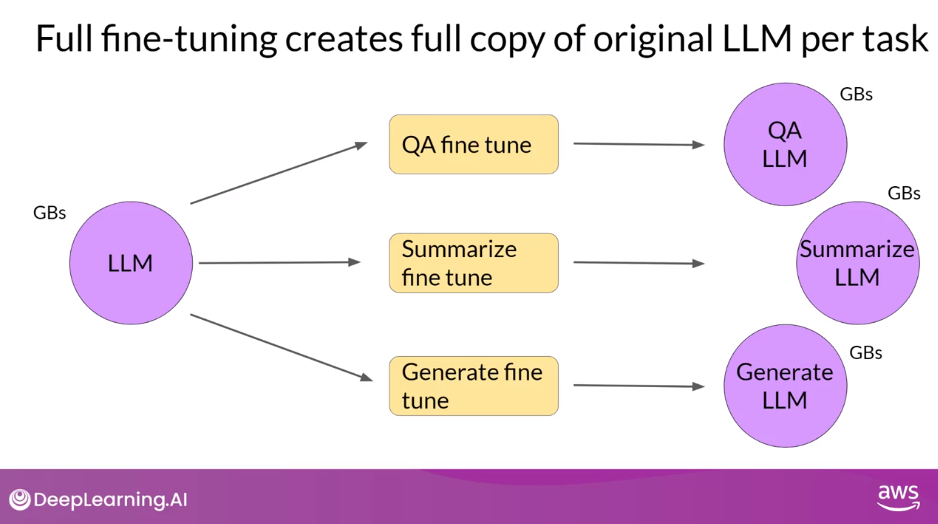
- Full fine-tuning results in a new version of the model for every task you train on.
- Each of these is the same size as the original model, so it can create an expensive storage problem if you’re fine-tuning for multiple tasks
PEFT Saves Space and is Flexible
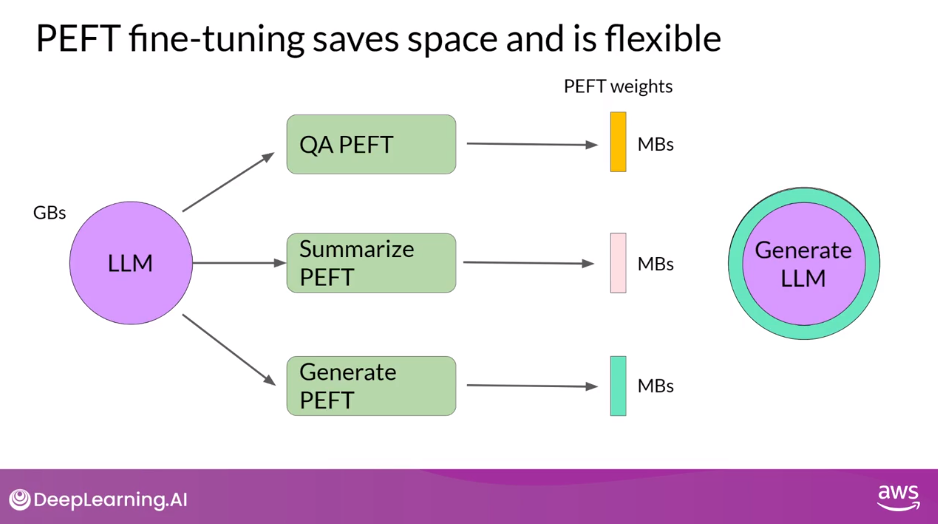
- With parameter efficient fine-tuning, you train only a small number of weights, which results in a much smaller footprint overall, as small as megabytes depending on the task.
- The new parameters are combined with the original LLM weights for inference.
- The PEFT weights are trained for each task and can be easily swapped out for inference, allowing efficient adaptation of the original model to multiple tasks
PEFT Trade-offs
- There are several methods you can use for parameter efficient fine-tuning, each with trade-offs on parameter efficiency, memory efficiency, training speed, model quality, and inference costs

PEFT Methods
- Let’s take a look at the three main classes of PEFT methods.
- Selective methods are those that fine-tune only a subset of the original LLM parameters. There are several approaches that you can take to identify which parameters you want to update. You have the option to train only certain components of the model or specific layers, or even individual parameter types. Researchers have found that the performance of these methods is mixed and there are significant trade-offs between parameter efficiency and compute efficiency. We won’t focus on them in this course.
- Reparameterization methods also work with the original LLM parameters, but reduce the number of parameters to train by creating new low rank transformations of the original network weights. A commonly used technique of this type is LoRA, which we’ll explore in detail in the next video.
- Lastly, Additive methods carry out fine-tuning by keeping all of the original LLM weights frozen and introducing new trainable components. Here there are two main approaches.
- Adapter methods add new trainable layers to the architecture of the model, typically inside the encoder or decoder components after the attention or feed-forward layers.
- Soft Prompt methods, on the other hand, keep the model architecture fixed and frozen, and focus on manipulating the input to achieve better performance. This can be done by adding trainable parameters to the prompt embeddings or keeping the input fixed and retraining the embedding weights. In this lesson, you’ll take a look at a specific soft prompts technique called prompt tuning
Question:
“Parameter Efficient Fine-Tuning (PEFT) updates only a small subset of parameters. This helps prevent catastrophic forgetting.” True or False?
True
Correct Performing full-finetuning can lead to catastrophic forgetting because it changes all parameters on the model. Since PEFT only updates a small subset of parameters, it’s more robust against this catastrophic forgetting effect.
PEFT Techniques 1: LoRA
- Low-rank Adaptation, or LoRA for short, is a parameter-efficient fine-tuning technique that falls into the Reparameterization category
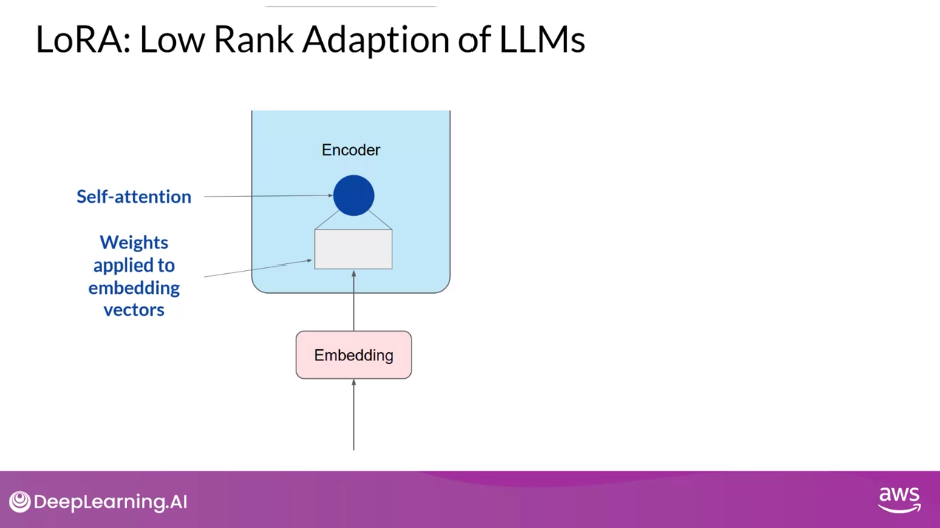
Transformers Recap
- The input prompt is turned into tokens, which are then converted to embedding vectors and passed into the encoder and/or decoder parts of the transformer.
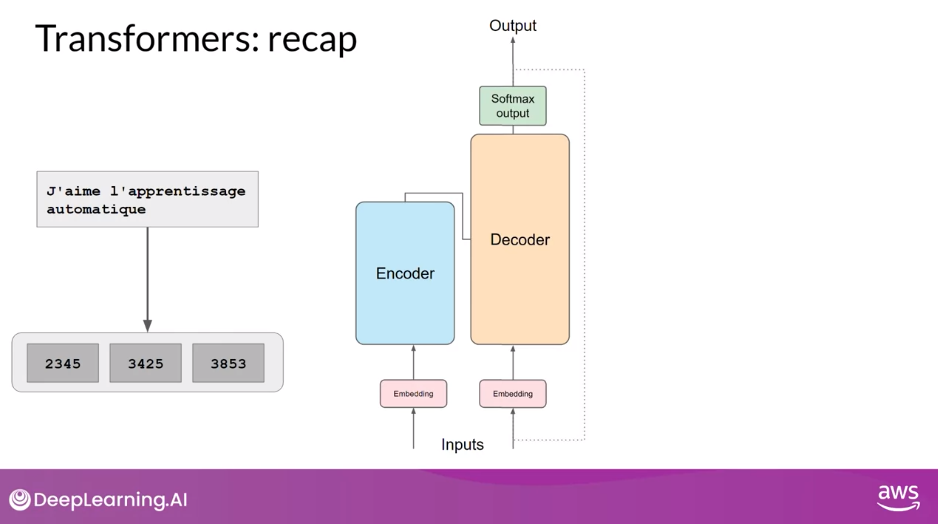
- In both of these components, there are two kinds of neural networks;
- self-attention and
- feedforward networks.
- The weights of these networks are learned during pre-training.
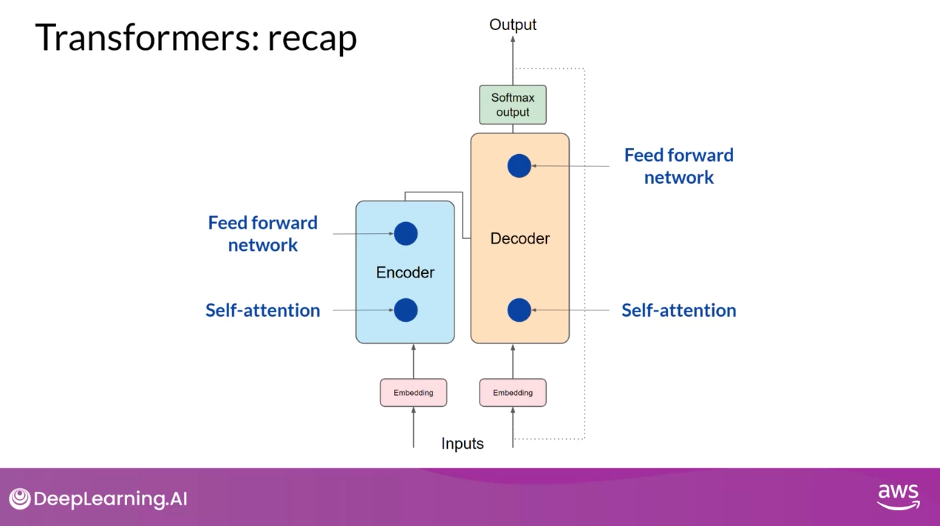
- After the embedding vectors are created, they’re fed into the self-attention layers where a series of weights are applied to calculate the attention scores
- During full fine-tuning, every parameter in these layers is updated
LoRA
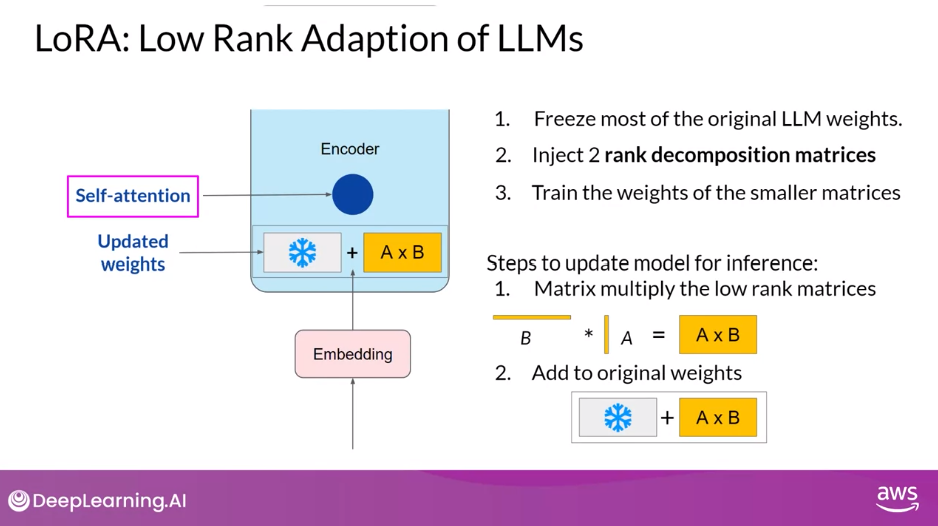
- LoRA is a strategy that reduces the number of parameters to be trained during fine-tuning by freezing all of the original model parameters and then injecting a pair of rank decomposition matrices alongside the original weights.
- The dimensions of the smaller matrices are set so that their product is a matrix with the same dimensions as the weights they’re modifying.
- You then keep the original weights of the LLM frozen and train the smaller matrices using the same supervised learning process you saw earlier this week.
- For inference,
- The two low-rank matrices are multiplied together to create a matrix with the same dimensions as the frozen weights.
- You then add this to the original weights and replace them in the model with these updated values
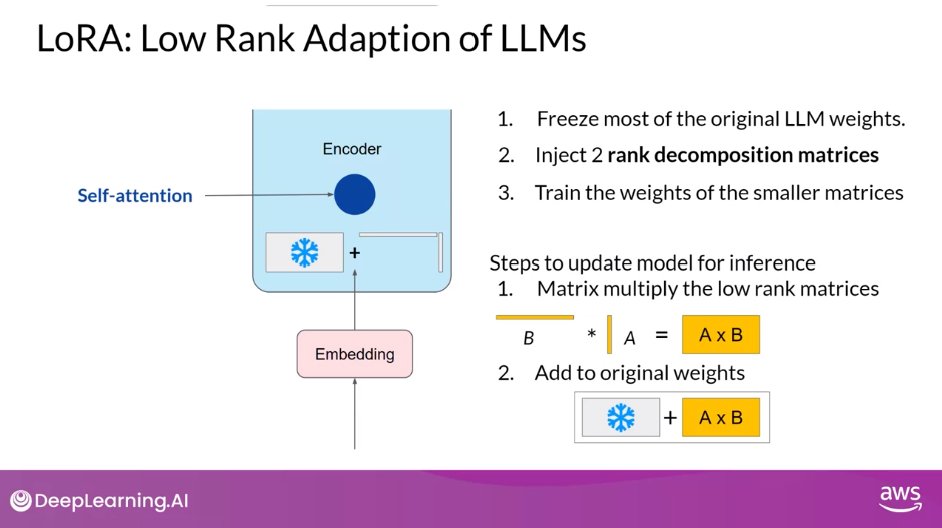
- You now have a LoRA fine-tuned model that can carry out your specific task.
- Because this model has the same number of parameters as the original, there is little to no impact on inference latency.
- Researchers have found that applying LoRA to just the self-attention layers of the model is often enough to fine-tune for a task and achieve performance gains.
- However, in principle, you can also use LoRA on other components like the feed-forward layers.
- But since most of the parameters of LLMs are in the attention layers, you get the biggest savings in trainable parameters by applying LoRA to these weights matrices
LoRA Example
- Let’s look at a practical example using the transformer architecture described in the Attention is All You Need paper.
- The paper specifies that the transformer weights have dimensions of 512 by 64, this means that each weights matrix has 32,768 trainable parameters.
- If you use LoRA as a fine-tuning method with the rank equal to eight (r=8), you will instead train two small rank decomposition matrices whose small dimension is eight.
- This means that Matrix A will have dimensions of 8 by 64, resulting in 512 total parameters.
- A has dimensions r x k = 8 x 64 = 512 parameters
- Matrix B will have dimensions of 512 by 8, or 4,096 trainable parameters.
- B has dimensions d x r = 512 x 8 = 4096 parameters
- This means that Matrix A will have dimensions of 8 by 64, resulting in 512 total parameters.
- By updating the weights of these new low-rank matrices instead of the original weights, you’ll be training 4,608 parameters instead of 32,768 and 86% reduction

- Because LoRA allows you to significantly reduce the number of trainable parameters, you can often perform this method of parameter efficient fine tuning with a single GPU and avoid the need for a distributed cluster of GPUs
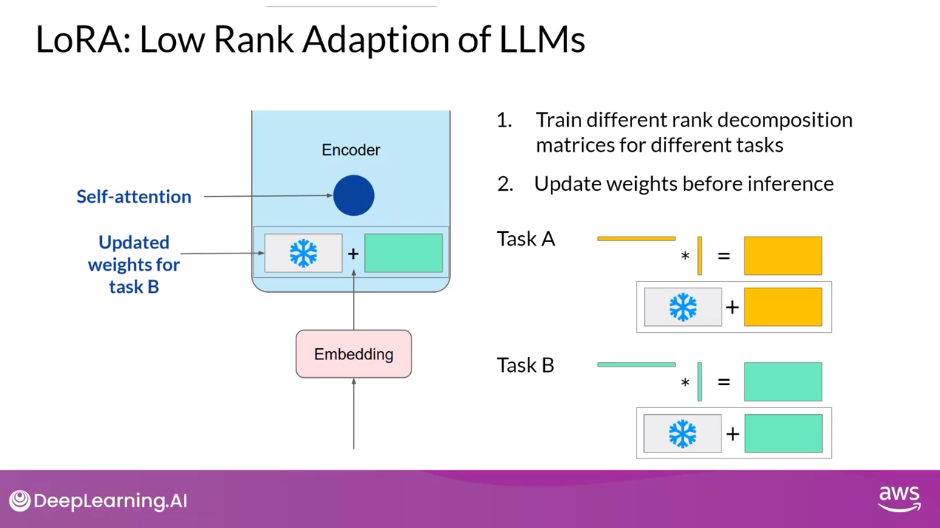
Train on Different Tasks
- Since the rank-decomposition matrices are small, you can
- fine-tune a different set for each task and then
- switch them out at inference time by updating the weights.
- Suppose you train a pair of LoRA matrices for a specific task; let’s call it Task A.
- To carry out inference on this task, you would multiply these matrices together and then add the resulting matrix to the original frozen weights.
- You then take this new summed weights matrix and replace the original weights where they appear in your model.
- You can then use this model to carry out inference on Task A.
- If instead, you want to carry out a different task, say Task B, you simply take the LoRA matrices you trained for this task, calculate their product, and then add this matrix to the original weights and update the model again.
- The memory required to store these LoRA matrices is very small.
- So in principle, you can use LoRA to train for many tasks.
- Switch out the weights when you need to use them, and avoid having to store multiple full-size versions of the LLM
Performance of LoRA
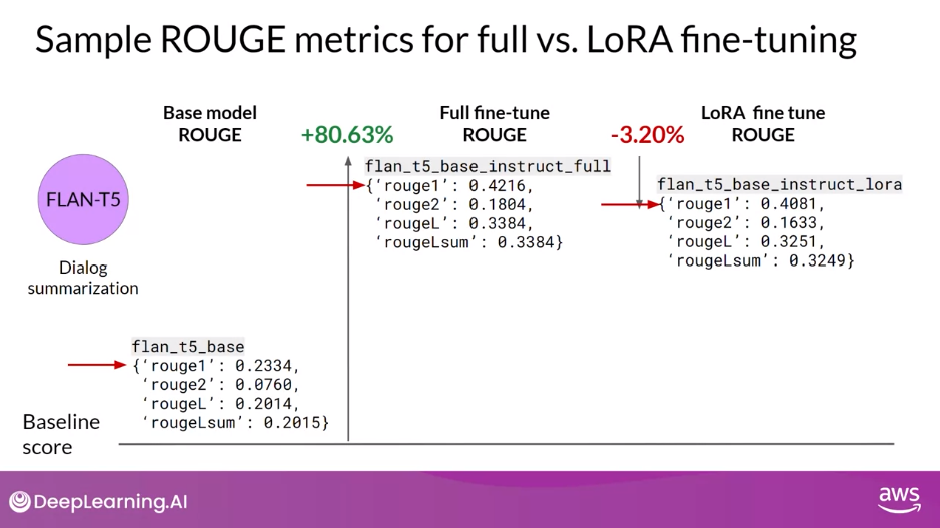
- Let’s use the ROUGE metric you learned about earlier this week to compare the performance of a LoRA fine-tune model to both an original base model and a full fine-tuned version
- Let’s focus on fine-tuning the FLAN-T5 for dialogue summarization, which you explored earlier in the week.
- Just to remind you, the FLAN-T5-base model has had an initial set of full fine-tuning carried out using a large instruction data set.
- First, let’s set a baseline score for the FLAN-T5 base model and the summarization data set we discussed earlier.
- Here are the ROUGE scores for the base model where a higher number indicates better performance.
- You should focus on the ROUGE 1 score for this discussion, but you could use any of these scores for comparison.
- As you can see, the scores are fairly low.
- Next, look at the scores for a model that has had additional full fine-tuning on dialogue summarization.
- Remember, although FLAN-T5 is a capable model, it can still benefit from additional fine-tuning on specific tasks
- With full fine-tuning, you update every way in the model during supervised learning.
- You can see that this results in a much higher ROUGE 1 score increasing over the base FLAN-T5 model by 0.19.
- The additional round of fine-tuning has greatly improved the performance of the model on the summarization task
- Now let’s take a look at the scores for the LoRA fine-tune model.
- You can see that this process also resulted in a big boost in performance.
- The ROUGE 1 score has increased from the baseline by 0.17.
- This is a little lower than full fine-tuning, but not much.
- However, using LoRA for fine-tuning trained a much smaller number of parameters than full fine-tuning using significantly less compute, so this small trade-off in performance may well be worth it
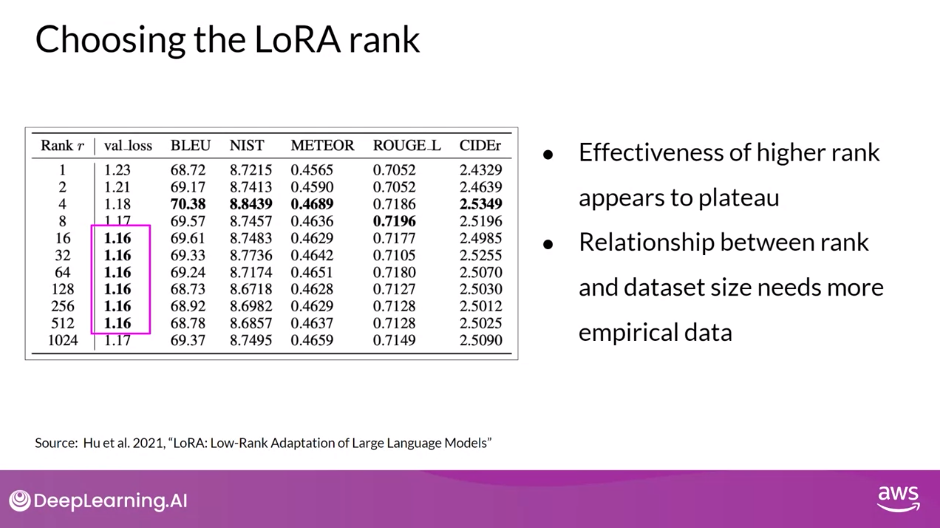
Choosing the LoRA Rank
- Still an active area of research.
- In principle, the smaller the rank, the smaller the number of trainable parameters, and the bigger the savings on compute.
- In the paper that first proposed LoRA, researchers at Microsoft explored how different choices of rank impacted the model performance on language generation tasks.
- The table shows the rank of the LoRA matrices in the first column, the final loss value of the model, and the scores for different metrics, including BLEU and ROUGE.
- The bold values indicate the best scores that were achieved for each metric.
- The authors found a plateau in the loss value for ranks greater than 16. In other words, using larger LoRA matrices didn’t improve performance.
- The takeaway here is that ranks in the range of 4-32 can provide you with a good trade-off between reducing trainable parameters and preserving performance.
- Optimizing the choice of rank is an ongoing area of research and best practices may evolve as more practitioners like you make use of LoRA.
LoRA is a powerful fine-tuning method that achieves great performance.
The principles behind the method are useful not just for training LLMs, but for models in other domains.
The final path method that you’ll explore this week doesn’t change the LLM at all and instead focuses on training your input text.
PEFT Techniques 2: Soft Prompts
- With LoRA, the goal was to find an efficient way to update the weights of the model without having to train every single parameter again. There are also additive methods within PEFT that aim to improve model performance without changing the weights at all
- A second parameter efficient fine-tuning method called Prompt Tuning
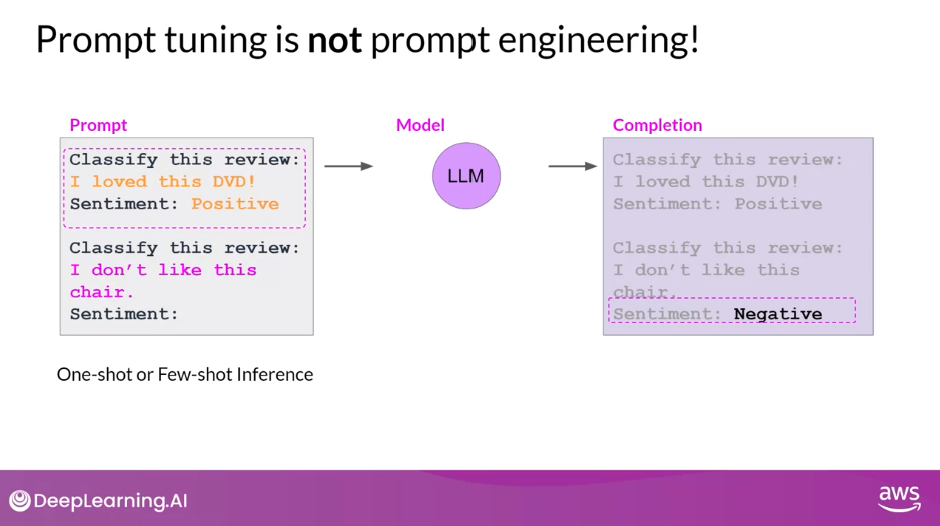
Prompt Tuning is Not Prompt Engineering
- With prompt engineering, you work on the language of your prompt to get the completion you want.
- This could be as simple as trying different words or phrases or more complex, like including examples for one or few-shot Inference.
- The goal is to help the model understand the nature of the task you’re asking it to carry out and to generate a better completion.
- However, there are some limitations to prompt engineering, as it can require a lot of manual effort to write and try different prompts.
- You’re also limited by the length of the context window, and at the end of the day, you may still not achieve the performance you need for your task
Prompt Tuning
- With prompt tuning, you add additional trainable tokens to your prompt and leave it up to the supervised learning process to determine their optimal values.
- The set of trainable tokens is called a soft prompt, and it gets prepended to embedding vectors that represent your input text.
- The soft prompt vectors have the same length as the embedding vectors of the language tokens.
- And including somewhere between 20 and 100 virtual tokens can be sufficient for good performance

Soft Prompts
- The tokens that represent natural language are hard in the sense that they each correspond to a fixed location in the embedding vector space.
- However, the soft prompts are not fixed discrete words of natural language
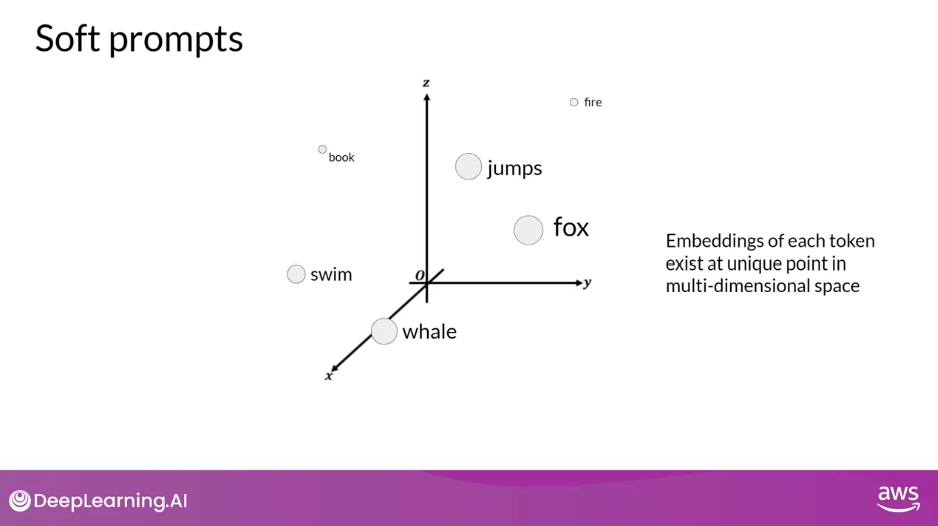
- Instead, you can think of them as virtual tokens that can take on any value within the continuous multidimensional embedding space.
- And through supervised learning, the model learns the values for these virtual tokens that maximize performance for a given task
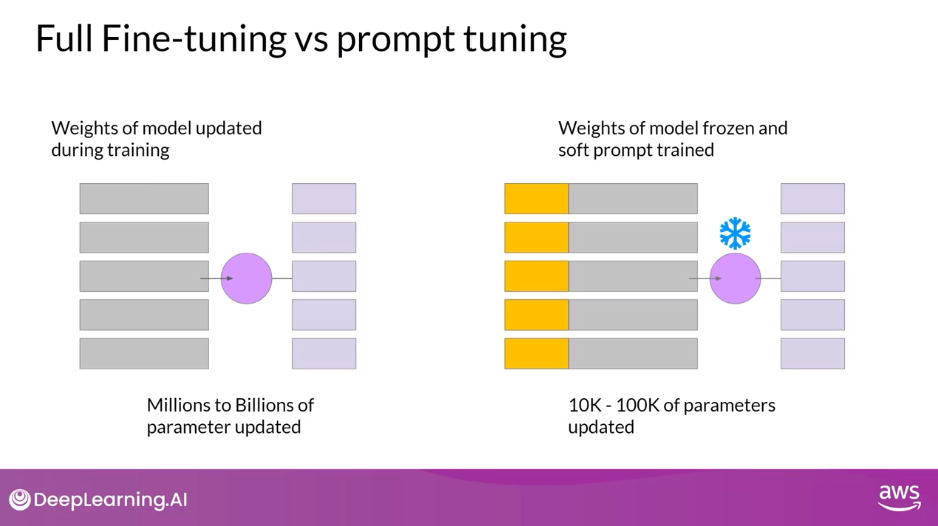
Full Fine-tuning vs Prompt Tuning
- In Full Fine-tuning, the training data set consists of input prompts and output completions or labels.
- The weights of the large language model are updated during supervised learning
- In contrast, with Prompt Tuning, the weights of the large language model are frozen and the underlying model does not get updated.
- Instead, the embedding vectors of the soft prompt gets updated over time to optimize the model’s completion of the prompt
- Prompt tuning is a very parameter efficient strategy because only a few parameters are being trained, in contrast with the millions to billions of parameters in full fine-tuning
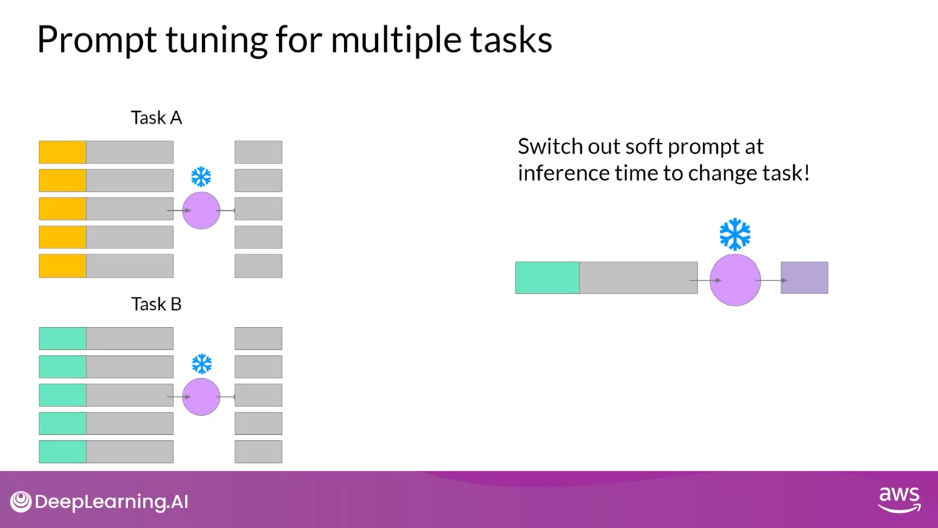
Prompt Tuning for Multiple Tasks
- Similar to what you saw with LoRA, you can train a different set of soft prompts for each task and then easily swap them out at inference time.
- You can train a set of soft prompts for one task and a different set for another
- To use them for inference, you prepend your input prompt with the learned tokens to switch to another task, you simply change the soft prompt.
- Soft prompts are very small on disk, so this kind of fine tuning is extremely efficient and flexible.
- You’ll notice the same LLM is used for all tasks, all you have to do is switch out the soft prompts at inference time
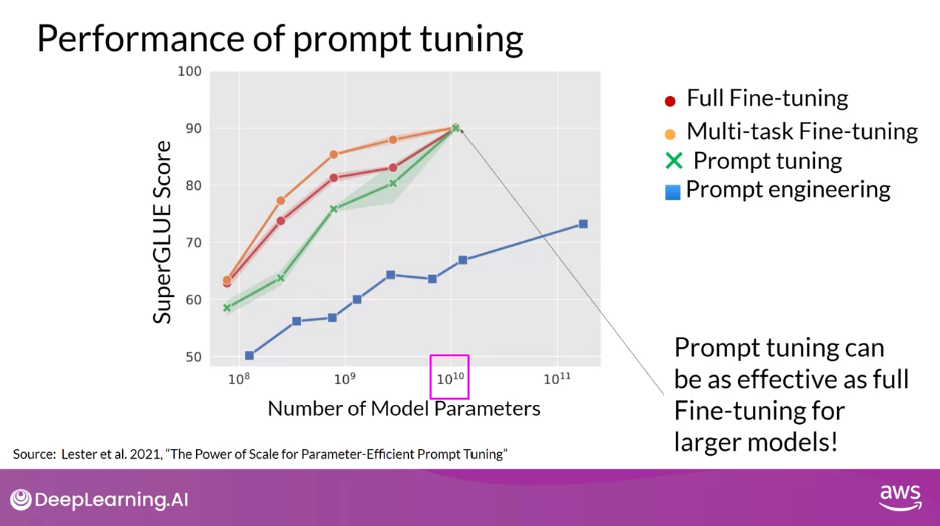
Performance of Prompt Tuning
- In the original paper exploring the method by Brian Lester and collaborators at Google, the authors compared prompt tuning to several other methods for a range of model sizes.
- In this figure from the paper, you can see the Model size on the X axis and the SuperGLUE score on the Y axis.
- This is the evaluation benchmark you learned about earlier this week that grades model performance on a number of different language tasks.
- The red line shows the scores for models that were created through full fine tuning on a single task.
- While the orange line shows the score for models created using multitask fine tuning.
- The green line shows the performance of prompt tuning and finally, the blue line shows scores for prompt engineering only.
- As you can see, prompt tuning doesn’t perform as well as full fine tuning for smaller LLMs.
- However, as the model size increases, so does the performance of prompt tuning.
- And once models have around 10 billion parameters, prompt tuning can be as effective as full fine-tuning and offers a significant boost in performance over prompt engineering alone
Interpretability of Soft Prompts
- One potential issue to consider is the interpretability of learned virtual tokens.
- Remember, because the soft prompt tokens can take any value within the continuous embedding vector space.
- The trained tokens don’t correspond to any known token, word, or phrase in the vocabulary of the LLM
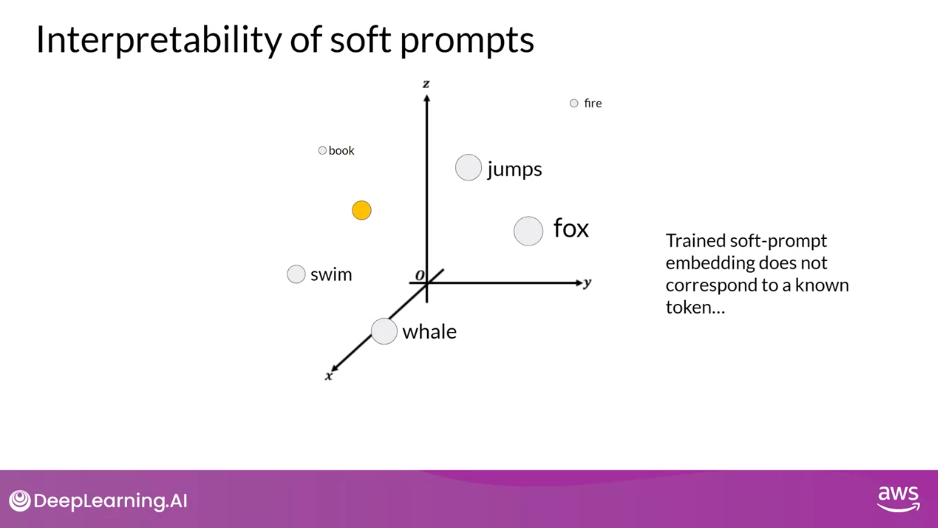
- However, an analysis of the nearest neighbor tokens to the soft prompt location shows that they form tight semantic clusters.
- In other words, the words closest to the soft prompt tokens have similar meanings.
- The words identified usually have some meaning related to the task, suggesting that the prompts are learning word like representations

Summary: PEFT Methods
- You explored two PEFT methods in this lesson LoRA, which uses rank decomposition matrices to update the model parameters in an efficient way.
- And Prompt Tuning, where trainable tokens are added to your prompt and the model weights are left untouched.
- Both methods enable you to fine tune models with the potential for improved performance on your tasks while using much less compute than full fine-tuning methods
- LoRA is broadly used in practice because of the comparable performance to full fine tuning for many tasks and data sets
Key Takeaways
- Walked through how to adapt a foundation model through a process called Instruction Fine-tuning.
- Along the way, you saw some of the prompt templates and data sets that were used to train the FLAN-T5 model.
- You also saw how to use evaluation metrics and benchmarks such as ROUGE and HELM to measure success during model finetuning.
- In practice instruction finetuning has proven very effective and useful across a wide range of natural language use cases and tasks.
- With just a few hundred examples, you can fine tune a model to your specific task, which is truly amazing.
- Next, you saw how parameter efficient fine-tuning, or PEFT, can reduce the amount of compute required to finetune a model.
- You learned about two methods you can use for this LoRA and Prompt Tuning.
- By the way you can also combine LoRA with the quantization techniques you learned about in week 1 to further reduce your memory footprint. This is known as QLoRA
In practice, PEFT is used heavily to minimize compute and memory resources. And ultimately reducing the cost of fine-tuning, allowing you to make the most of your compute budget and speed up your development process
Question: Parameter Efficient Fine-Tuning (PEFT) methods specifically attempt to address some of the challenges of performing full fine-training. Which of the following options describe challenges that PEFT tries to overcome?
Computational constraints
Correct
Because most parameters are frozen, we typically only need to train 15%-20% of the original LLM weights, making the training process less expensive (less memory required)
Storage requirements
Correct
With PEFT, we can change just a small amount of parameters when fine-tuning, so during inference you can combine the original model with the new parameters, instead of duplicating the entire model for each new task you want to perform fine-tuning.
Catastrophic forgetting
Correct
With PEFT, most parameters of the LLM are unchanged, and that helps making it less prone to catastrophic forgetting.
Lab 2 Walkthrough
- Try out fine-tuning using PEFT with LoRA for yourself by improving the summarization ability of the Flan-T5 model (flan-t5-base)
- hands-on with full fine-tuning and Parameter-Efficient Fine-Tuning, also called PEFT with prompt instructions. You will tune the Flan-T5 model further with your own specific prompts for your specific summarization task
- Lab 1, we were doing the zero-shot inference, the in-context learning. Now we are actually going to modify the weights of our language model, specific to our summarization task and specific to our dataset
- Compare original model and instruction-fine-tuned model
- PEFT
- makes such a big difference, especially when you’re constrained by how much compute resources that you have, you can lower the footprint both memory, disk, GPU, CPU, all of the resources can be reduced just by introducing PEFT into your fine-tuning process
- In the lessons you learned about LoRA, you learned about the rank. Here we’re going to choose rank of 32, which is actually relatively high. But we are just starting with that. Here it’s the SEQ_2_SEQ_LM, this is FLAN-T5. With just a few extra lines of code here to configure our LoRA fine-tuning. Then here we see we’re only going to train 1.4 percent of the trainable model parameters. In a lot of cases you can fine-tune very large models on a single GPU
- called the PEFT adapters or LoRA adopters, get merged or combined with the original LLM
- have to take the original LLM and then merge in this LoRA PEFT adapter
- can actually set the is_trainable flag to false. By setting the is_trainable flag to false, we are telling PyTorch that we’re not interested in training this model. All we’re interested in doing is the forward pass just to get the summaries. This is significant because we can tell PyTorch to not load any of the update portions of these operators and to basically minimize the footprint needed to just perform the inference with this model. This is a pretty neat flag. This was actually just introduced recently into the PEFT model at the time of this lab. I wanted to show it here because this is a pattern that you want to try to find when you’re doing your own modeling. When you know that you’re ready to deploy the model for inference, there are usually ways that you can hint to the framework, such as PyTorch that you’re not going to be training. This can then further reduce the resources needed to make these predictions
- PEFT - use much less resources during fine-tuning, than we would have if we did the full instruction. You can imagine this is only just a few thousand samples, but you can imagine at scale how this really can save you tons of compute resources and time by using PEFT by looking at the larger data set
Lab 2 - Fine-tune a Generative AI Model For Dialogue Summarization
- You will fine-tune an existing LLM from Hugging Face for enhanced dialogue summarization.
- You will use the FLAN-T5 (flan-t5-base) model, which provides a high quality instruction-tuned model and can summarize text out of the box.
- To improve the inferences, you will explore a full fine-tuning approach and evaluate the results with ROUGE metrics.
- Then you will perform PEFT fine-tuning, evaluate the resulting model and see that the benefits of PEFT outweigh the slightly-lower performance metrics