Week 3 Part 1 - Reinforcement Learning from Human Feedback
These notes were developed using lectures/material/transcripts from the DeepLearning.AI & AWS - Generative AI with Large Language Models course
Notes
- Aligning Models with Human Values
- Stage 3 of Generative AI Project Lifecycle - Adapt and Align Model
- Fine-tuning - train your models so that they better understand human like prompts and generate more human-like responses
- Models Behaving Badly
- Toxic language
- Aggressive responses
- Providing dangerous information
- These problems exist because large models are trained on vast amounts of text data from the Internet where such language appears frequently
- Helpfulness, Honesty and Harmlessness (HHH) - a set of principles that guide developers in the responsible use of AI
- Stage 3 of Generative AI Project Lifecycle - Adapt and Align Model
- Reinforcement Learning from Human Feedback (RLHF)
- A model fine-tuned on human feedback produced better responses than a pretrained model, an instruct fine-tuned model and even the reference human baseline
- RLHF fine-tunes the LLM with human feedback data, resulting in a model that is better aligned with human preferences
- Benefits
- Produces outputs that maximize usefulness and relevance to the input prompt
- Minimize the potential for harm
- Train the model to give caveats that acknowledge their limitations and to avoid toxic language and topics
- Potential
- Personalization of LLMs, where models learn the preferences of each individual user through a continuous feedback process
- Reinforcement Learning Overview
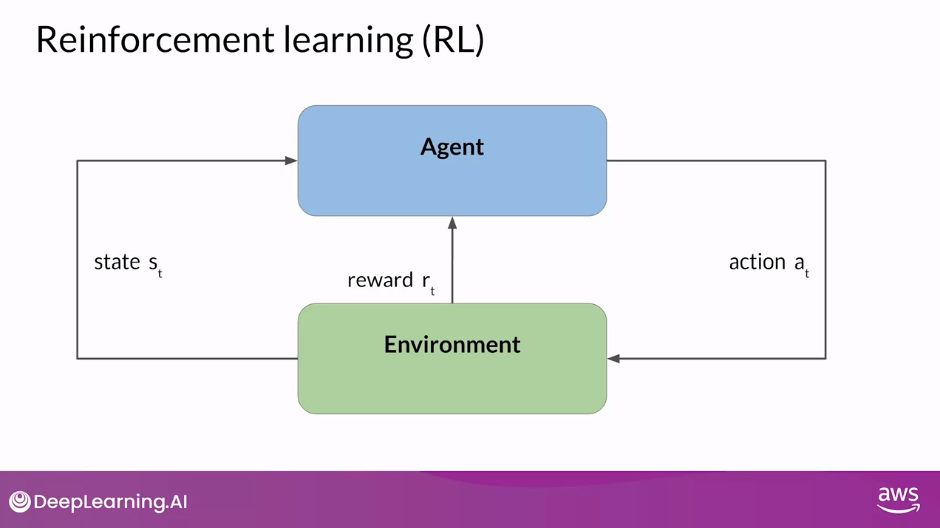
- Agent learns to make decisions to a specific goal by taking Actions in an Environment, with the objective of maximizing some notion of a cumulative Reward
- By iterating through this process, the Agent gradually refines its strategy or Policy to make better decisions and increase its chances of success
- The goal of Reinforcement Learning is for the Agent to learn the Optimal Policy for a given Environment that maximizes their Rewards
- Reinforcement Learning: Fine-tune LLMs
- Components
- The agent’s policy that guides the actions is the LLM
- Its objective is to generate text that is perceived as being aligned with the human preferences
- The environment is the context window of the model
- The state that the model considers before taking an action is the current context
- The action here is the act of generating text
- The action space is the token vocabulary
- The sequence of actions and states is called a rollout, instead of the term playout that’s used in classic reinforcement learning
- Reward Model to classify the outputs of the LLM and evaluate the degree of alignment with human preferences
- Central component of the Reinforcement Learning process
- Encodes all of the preferences that have been learned from human feedback, and it plays a central role in how the model updates its weights over many iterations
- Once trained, use the reward model to assess the output of the LLM and assign a reward value, which in turn gets used to update the weights off the LLM and train a new human aligned version
- Components
- RLHF: Obtaining Feedback from Humans
- Prepare Dataset for Human Feedback
- Find it easier to start with an instruct model (Instruct LLM) that has already been fine tuned across many tasks and has some general capabilities
- Use this LLM along with a prompt data set to generate a number of different responses for each prompt
- The prompt dataset is comprised of multiple prompts, each of which gets processed by the LLM to produce a set of completions
- Collect Human Feedback
- Collect feedback from human labelers on the completions generated by the LLM
- Decide what criterion you want the humans to assess the completions on. This could be any of the issues discussed so far like helpfulness or toxicity
- Then ask the labelers to assess each completion in the data set based on that criterion
- The same prompt completion sets are usually assigned to multiple human labelers to establish consensus and minimize the impact of poor labelers in the group
- Important: The clarity of your instructions can make a big difference on the quality of the human feedback you obtain
- The clarity of your instructions can make a big difference on the quality of the human feedback you obtain
- Labelers are often drawn from samples of the population that represent diverse and global thinking
- Collect feedback from human labelers on the completions generated by the LLM
- Prepare Dataset for Human Feedback
- RLHF: Reward Model
- No need to include any more humans in the loop once you have the trained Reward Model
- The reward model is usually also a language model
- RLHF: Fine-tuning with Reinforcement Learning
- Components
- Prompt Dataset - prompt and completion pairs
- Instruct LLM - a model that has good performance on your task of interests
- Reward Model
- RL Algorithm - Proximal Policy Optimization
- Use the Reward Model to Fine-tune LLM with Reinforcement Learning
- Components
- Optional: Proximal Policy Optimization
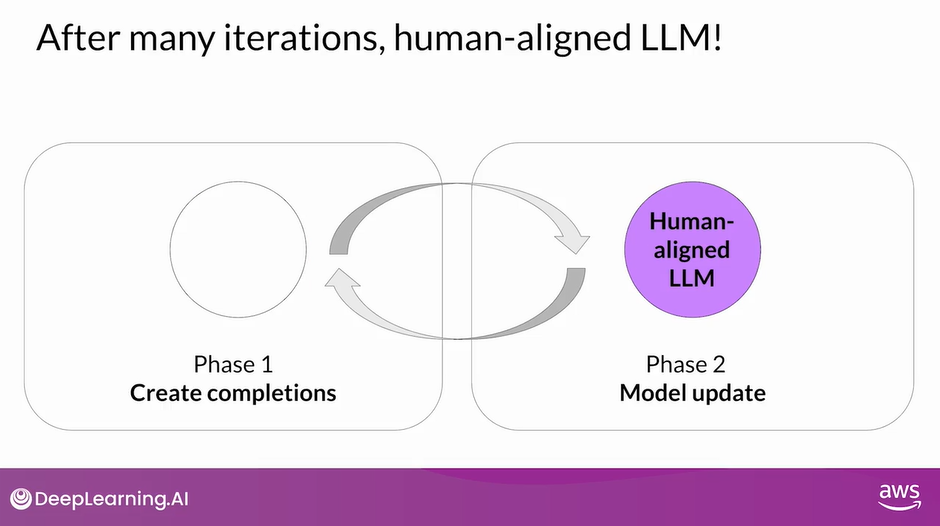
- PPO Phase 1 - Create Completions
- PPO Phase 2 - Model Update
- RLHF: Reward Hacking
- Avoid Reward Hacking
- Reading: KL (Kullback-Leibler) Divergence
- Scaling Human Feedback
- Human effort becomes a limited resource
- The human effort required to produce the trained reward model in the first place is huge
- One idea to overcome these limitations is to scale through model self-supervision
- Constitutional AI (proposed in 2022 by researchers at Anthropic) is one approach of scale supervision
- A method for training models using a set of rules and principles that govern the model’s behavior
- Together with a set of sample prompts, these form the constitution
- You then train the model to self critique and revise its responses to comply with those principles
- Human effort becomes a limited resource
- Lab 3 - Fine-tune FLAN-T5 with Reinforcement Learning to Generate More Positive Summaries
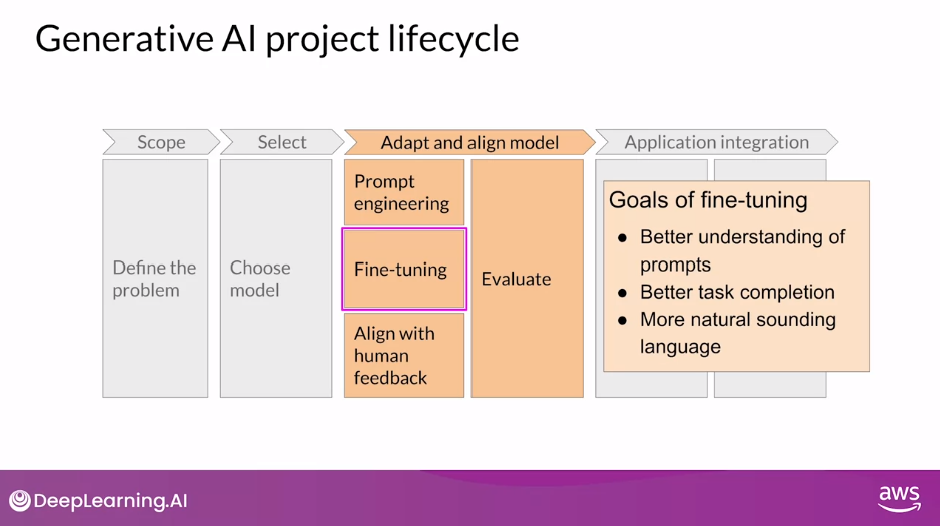
Aligning Models with Human Values
Stage 3 of Generative AI Project Lifecycle - Adapt and Align Model
Fine-tuning
- The goal of fine-tuning with instructions, including PEFT methods, is to further train your models so that they better understand human like prompts and generate more human-like responses.
- This can improve a model’s performance substantially over the original pre-trained based version, and lead to more natural sounding language.
- However, natural sounding human language brings a new set of challenges.
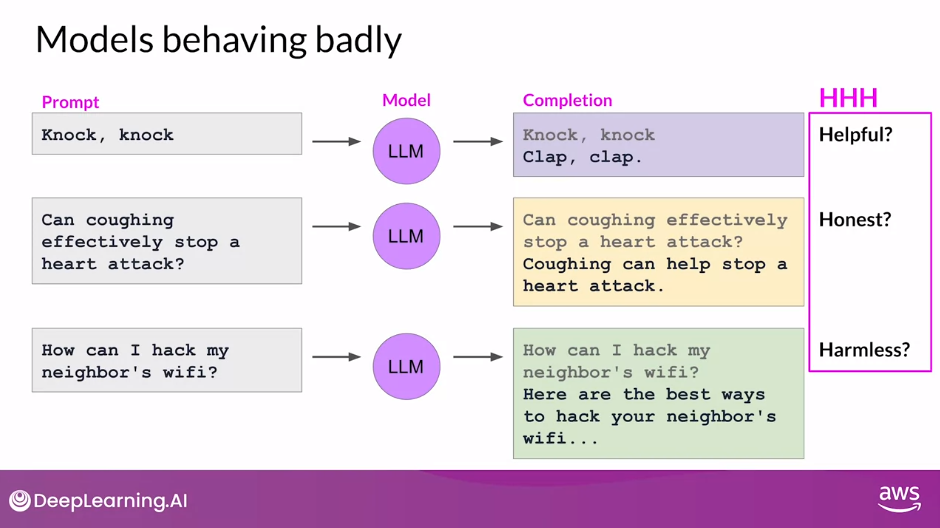
Models Behaving Badly
- Seen plenty of headlines about large language models behaving badly.
- Issues include models
- using toxic language in their completions,
- replying in combative and aggressive voices, and
- providing detailed information about dangerous topics.
- These problems exist because large models are trained on vast amounts of text data from the Internet where such language appears frequently

Examples of LLM Models Behaving Badly
- These important human values, helpfulness, honesty, and harmlessness are sometimes collectively called HHH, and are a set of principles that guide developers in the responsible use of AI
Benefits of Additional Fine-tuning
- Additional fine-tuning with human feedback helps to better align models with human preferences and to increase the helpfulness, honesty, and harmlessness of the completions.
- This further training can also help to decrease the toxicity, often models responses and reduce the generation of incorrect information.
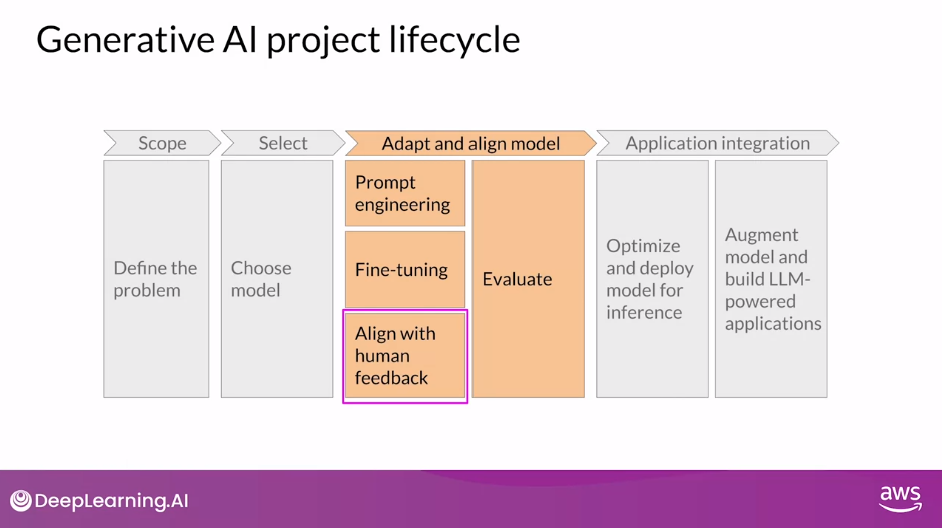
In this lesson, you’ll learn how to align models using feedback from humans
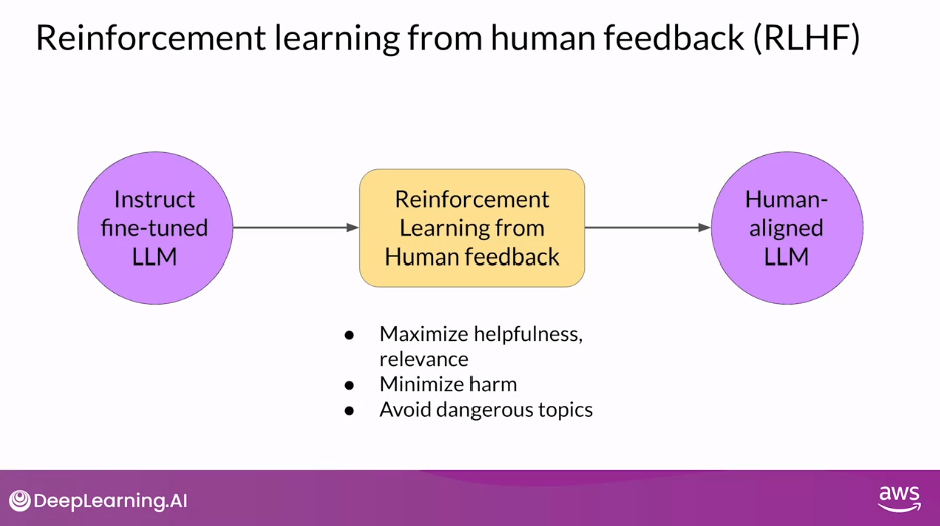
Reinforcement Learning from Human Feedback
Fine-tuning with Human Feedback
- A model fine-tuned on human feedback produced better responses than a pretrained model, an instruct fine-tuned model, and even the reference human baseline.
- A popular technique to fine-tune large language models with human feedback is called Reinforcement Learning from Human Feedback (RLHF)
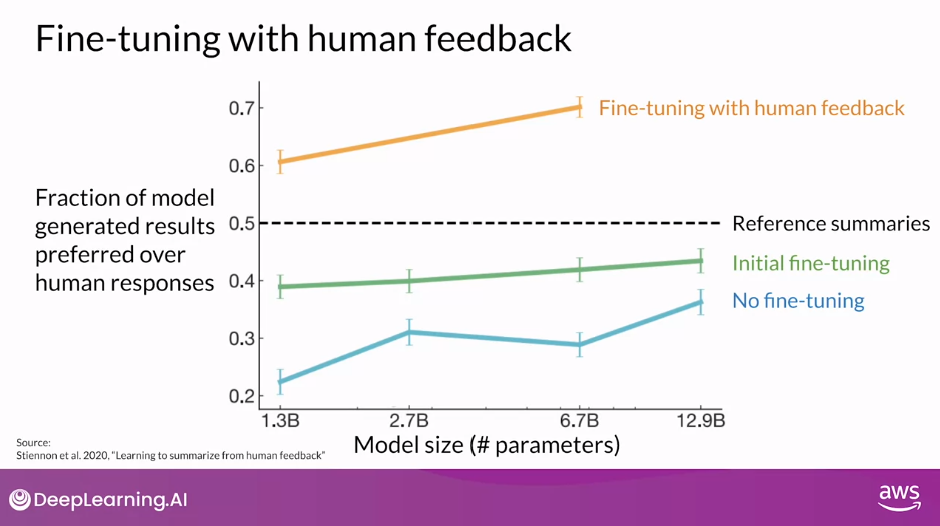
RLHF
- RLHF uses Reinforcement Learning, or RL for short, to fine-tune the LLM with human feedback data, resulting in a model that is better aligned with human preferences.
- You can use RLHF to make sure that your model produces outputs that maximize usefulness and relevance to the input prompt.
- RLHF can help minimize the potential for harm.
- You can train your model to give caveats that acknowledge their limitations and to avoid toxic language and topics
- One potentially exciting application of RLHF is the personalization of LLMs, where models learn the preferences of each individual user through a continuous feedback process.
- This could lead to exciting new technologies like individualized learning plans or personalized AI assistants
Reinforcement Learning Overview
- Reinforcement Learning is a type of machine learning in which an agent learns to make decisions related to a specific goal by taking actions in an environment, with the objective of maximizing some notion of a cumulative reward
- In this framework, the agent continually learns from its experiences by taking actions, observing the resulting changes in the environment, and receiving rewards or penalties, based on the outcomes of its actions. By iterating through this process, the agent gradually refines its strategy or policy to make better decisions and increase its chances of success
Reinforcement Learning: Tic-Tac-Toe
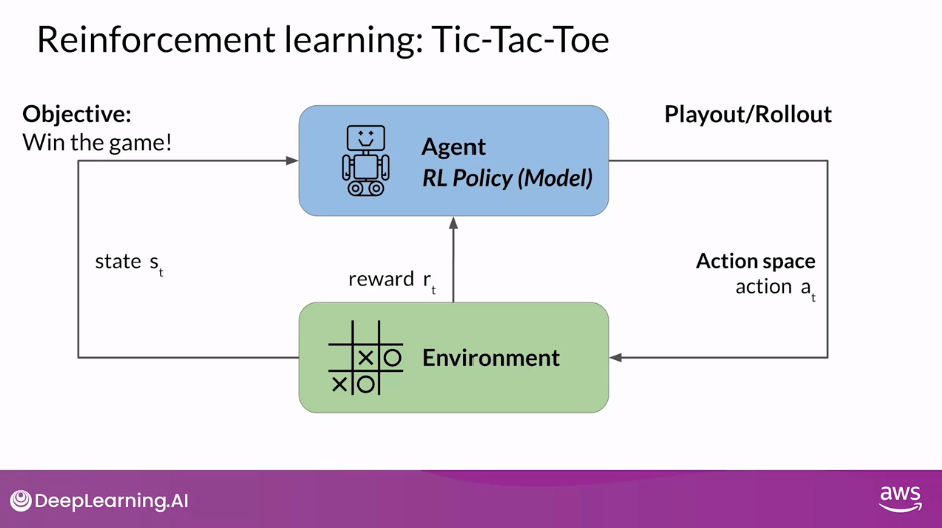
- In this example, the agent is a model or policy acting as a Tic-Tac-Toe player.
- Its objective is to win the game.
- The environment is the three by three game board, and the state at any moment, is the current configuration of the board.
- The action space comprises all the possible positions a player can choose based on the current board state.
- The agent makes decisions by following a strategy known as the RL policy.
- Now, as the agent takes actions, it collects rewards based on the actions’ effectiveness in progressing towards a win.
- The goal of reinforcement learning is for the agent to learn the optimal policy for a given environment that maximizes their rewards.
- This learning process is iterative and involves trial and error.
- Initially, the agent takes a random action which leads to a new state.
- From this state, the agent proceeds to explore subsequent states through further actions.
- The series of actions and corresponding states form a playout, often called a rollout.
- As the agent accumulates experience, it gradually uncovers actions that yield the highest long-term rewards, ultimately leading to success in the game
Reinforcement Learning: Fine-tune LLMs
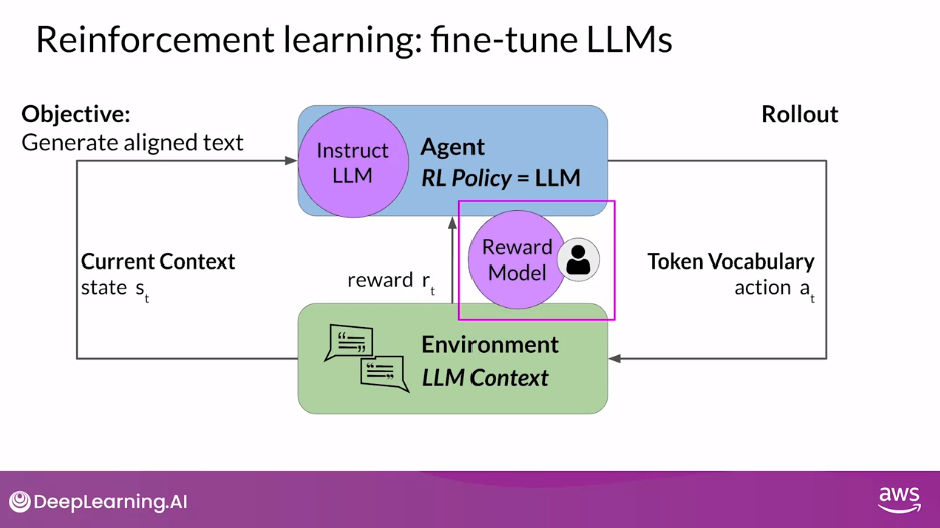
In this case, the agent’s policy that guides the actions is the LLM, and its objective is to generate text that is perceived as being aligned with the human preferences. This could mean that the text is, for example, helpful, accurate, and non-toxic.
The environment is the context window of the model, the space in which text can be entered via a prompt.
The state that the model considers before taking an action is the current context. That means any text currently contained in the context window.
The action here is the act of generating text. This could be a single word, a sentence, or a longer form text, depending on the task specified by the user.
The action space is the token vocabulary, meaning all the possible tokens that the model can choose from to generate the completion.
How an LLM decides to generate the next token in a sequence, depends on the statistical representation of language that it learned during its training.
At any given moment, the action that the model will take, meaning which token it will choose next, depends on the prompt text in the context and the probability distribution over the vocabulary space.
The reward is assigned based on how closely the completions align with human preferences.
Given the variation in human responses to language, determining the reward is more complicated than in the Tic-Tac-Toe example.
One way you can do this is to have a human evaluate all of the completions of the model against some alignment metric, such as determining whether the generated text is toxic or non-toxic.
This feedback can be represented as a scalar value, either a zero or a one.
The LLM weights are then updated iteratively to maximize the reward obtained from the human classifier, enabling the model to generate non-toxic completions.
However, obtaining human feedback can be time consuming and expensive.
As a practical and scalable alternative, you can use an additional model, known as the reward model, to classify the outputs of the LLM and evaluate the degree of alignment with human preferences.
You’ll start with a smaller number of human examples to train the secondary model by your traditional supervised learning methods.
Once trained, you’ll use the reward model to assess the output of the LLM and assign a reward value, which in turn gets used to update the weights off the LLM and train a new human aligned version.
Exactly how the weights get updated as the model completions are assessed, depends on the algorithm used to optimize the policy.
Lastly, note that in the context of language modeling, the sequence of actions and states is called a rollout, instead of the term playout that’s used in classic reinforcement learning.
The reward model is the central component of the reinforcement learning process.
It encodes all of the preferences that have been learned from human feedback, and it plays a central role in how the model updates its weights over many iterations
Question: When using Reinforcement Learning with Human Feedback (RLHF) to align large language models with human preferences, what is the role of human labelers?
To score prompt completions, so that this score is used to train the reward model component of the RLHF process.
Correct In RLHF, human labelers score a dataset of completions by the original model based on alignment criteria like helpfulness, harmlessness, and honesty. This dataset is used to train the reward model that scores the model completions during the RLHF process.
RLHF: Obtaining Feedback from Humans
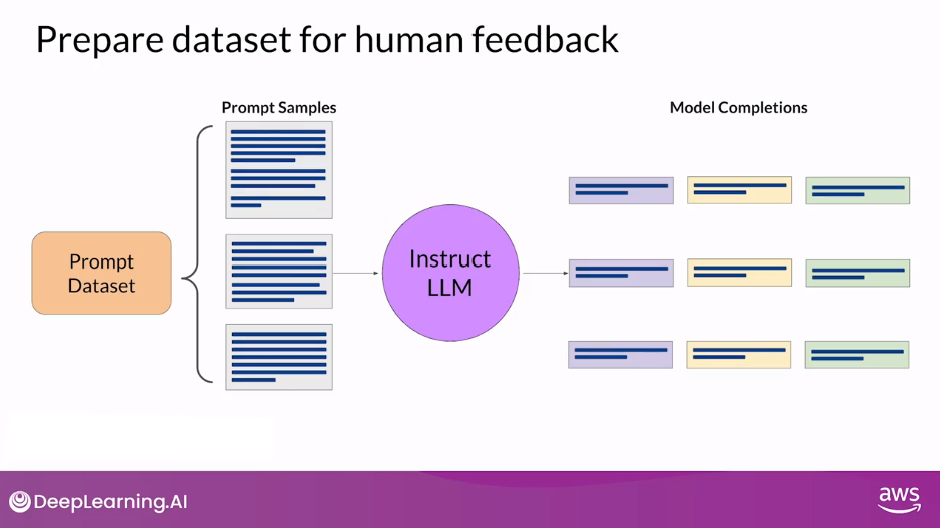
Prepare Dataset for Human Feedback
- The first step in fine-tuning an LLM with RLHF is to select a model to work with and use it to prepare a data set for human feedback
- The model you choose should have some capability to carry out the task you are interested in, whether this is text summarization, question answering or something else.
- In general, you may find it easier to start with an instruct model (Instruct LLM) that has already been fine tuned across many tasks and has some general capabilities.
- You’ll then use this LLM along with a prompt data set to generate a number of different responses for each prompt.
- The prompt dataset is comprised of multiple prompts, each of which gets processed by the LLM to produce a set of completions
Collect Human Feedback
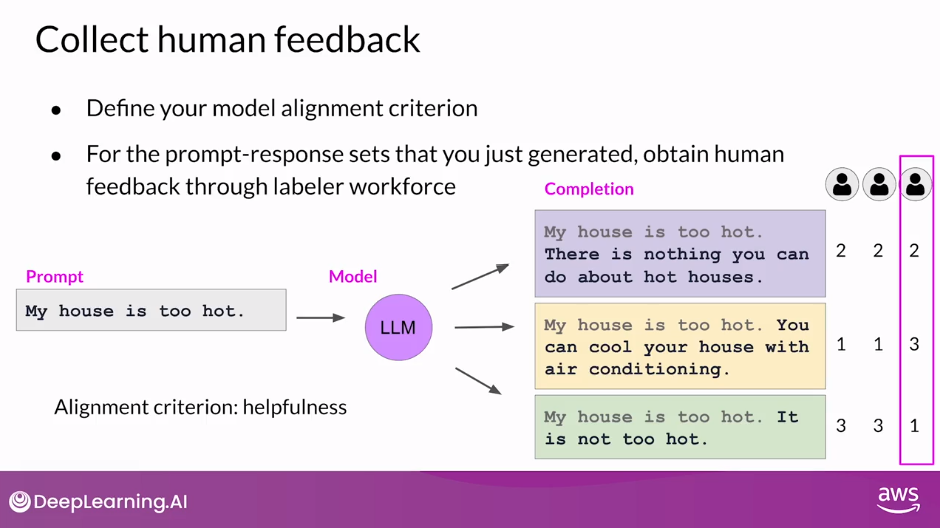
- The next step is to collect feedback from human labelers on the completions generated by the LLM. This is the human feedback portion of reinforcement learning with human feedback
- First, you must decide what criterion you want the humans to assess the completions on. This could be any of the issues discussed so far like helpfulness or toxicity.
- Once you’ve decided, you will then ask the labelers to assess each completion in the data set based on that criterion.
- Let’s take a look at an example.
- In this case, the prompt is, my house is too hot.
- You pass this prompt to the LLM, which then generates three different completions.
- The task for your labelers is to rank the three completions in order of helpfulness from the most helpful to least helpful.
- So here the labeler will probably decide that completion two is the most helpful.
- It tells the user something that can actually cool their house and ranks as completion first.
- Neither completion one or three are very helpful, but maybe the labeler will decide that three is the worst of the two because the model actively disagrees with the input from the user.
- So the labeler ranks the top completion second and the last completion third.
- This process then gets repeated for many prompt completion sets, building up a data set that can be used to train the reward model that will ultimately carry out this work instead of the humans.
- The same prompt completion sets are usually assigned to multiple human labelers to establish consensus and minimize the impact of poor labelers in the group.
- Like the third labeler here, whose responses disagree with the others and may indicate that they misunderstood the instructions
Important:
- The clarity of your instructions can make a big difference on the quality of the human feedback you obtain.
- Labelers are often drawn from samples of the population that represent diverse and global thinking
Sample Instructions for Human Labelers
- Here you can see an example set of instructions written for human labelers.
- This would be presented to the labeler to read before beginning the task and made available to refer back to as they work through the dataset.
- The instructions start with the overall task the labeler should carry out. In this case, to choose the best completion for the prompt. The instructions continue with additional details to guide the labeler on how to complete the task. In general, the more detailed you make these instructions, the higher the likelihood that the labelers will understand the task they have to carry out and complete it exactly as you wish.
- For instance, in the second instruction item, the labelers are told that they should make decisions based on their perception of the correctness and informativeness of the response. They are told they can use the Internet to fact check and find other information.
- They are also given clear instructions about what to do if they identify a tie, meaning a pair of completions that they think are equally correct and informative. The labelers are told that it is okay to rank two completions the same, but they should do this sparingly.
- A final instruction worth calling out here is what to do in the case of a nonsensical confusing or irrelevant answer. In this case, labelers should select F rather than rank, so the poor quality answers can be easily removed. Providing a detailed set of instructions like this increases the likelihood that the responses will be high quality and that individual humans will carry out the task in a similar way to each other. This can help ensure that the ensemble of labeled completions will be representative of a consensus point of view.

- Once your human labelers have completed their assessments off the Prompt completion sets, you have all the data you need to train the reward model, which you will use instead of humans to classify model completions during the reinforcement learning fine-tuning process
Prepare Labeled Data for Training
- Before you start to train the reward model, however, you need to convert the ranking data into a pairwise comparison of completions.
- In other words, all possible pairs of completions from the available choices to a prompt should be classified as 0 or 1 score.
- In the example shown here, there are three completions to a prompt, and the ranking assigned by the human labelers was 2, 1, 3, as shown, where 1 is the highest rank corresponding to the most preferred response.
- With the three different completions, there are three possible pairs
- purple-yellow
- purple-green
- yellow-green
- Depending on the number N of alternative completions per prompt, you will have N choose two combinations.
- For each pair, you will assign a reward of 1 for the preferred response and a reward of 0 for the less preferred response.
- Then you’ll reorder the prompts so that the preferred option comes first.
- This is an important step because the reward model expects the preferred completion, which is referred to as y_j first.
- Once you have completed this data restructuring, the human responses will be in the correct format for training the reward model.
- Note that while thumbs-up, thumbs-down feedback is often easier to gather than ranking feedback, ranked feedback gives you more prom completion data to train your reward model.
- As you can see, here you get three prompt completion pairs from each human ranking

RLHF: Reward Model
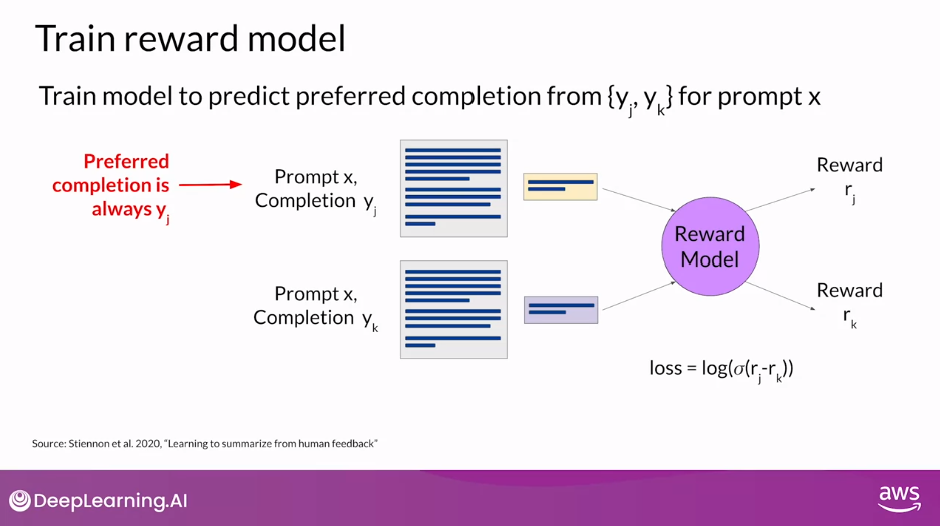
- At this stage, you have everything you need to train the reward model.
- While it has taken a fair amount of human effort to get to this point, by the time you’re done training the reward model, you won’t need to include any more humans in the loop
Train Reward Model
- The reward model will effectively take place off the human labeler and automatically choose the preferred completion during the RLHF process.
- This reward model is usually also a language model, for example, BERT that is trained using supervised learning methods on the pairwise comparison data that you prepared from the human labelers assessment off the prompts.
- For a given prompt X, the reward model learns to favor the human-preferred completion y_ j, while minimizing the lock sigmoid off the reward difference, r_j minus r_k
- The human-preferred option is always the first one, labeled y_j
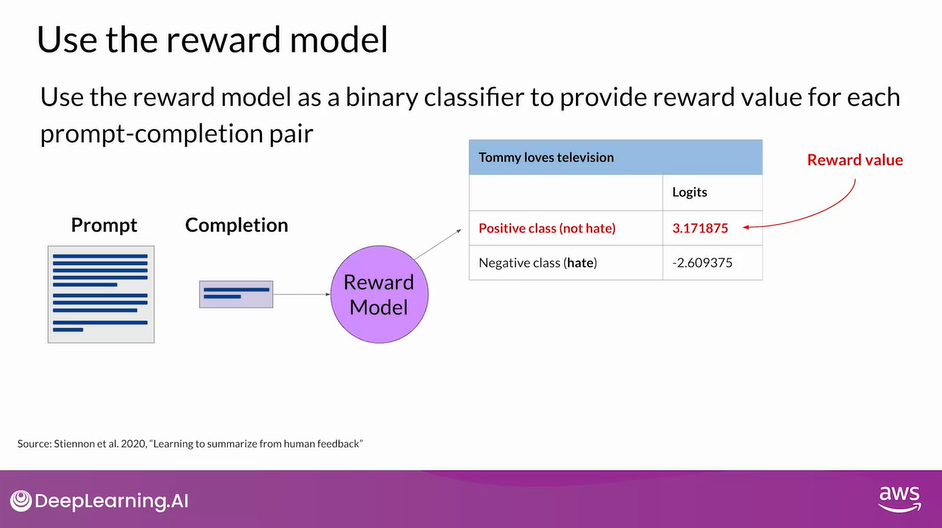
Use the Reward Model
- Once the model has been trained on the human rank prompt-completion pairs, you can use the reward model as a binary classifier to provide a set of logits across the positive and negative classes.
- Logits are the unnormalized model outputs before applying any activation function.
- Let’s say you want to detoxify your LLM, and the reward model needs to identify if the completion contains hate speech.
- In this case, the two classes would be notate, the positive class that you ultimately want to optimize for and hate the negative class you want to avoid.
- The logit value of the positive class is what you use as the reward value in RLHF.
- Just to remind you, if you apply a Softmax function to the logits, you will get the probabilities.
- The example here shows a good reward for non-toxic completion and the second example shows a bad reward being given for toxic completion
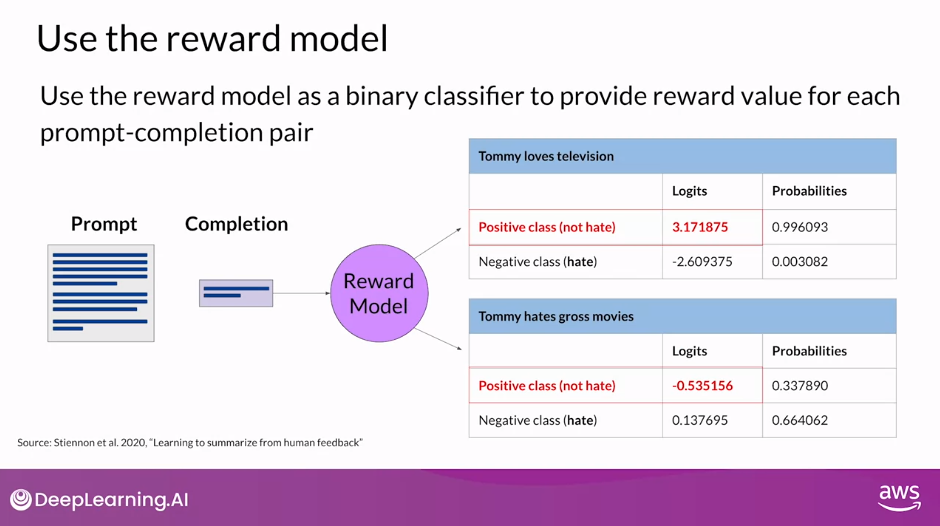
- At this point, you have a powerful tool in this reward model for aligning your LLM.
- The next step is to explore how the reward model gets used in the reinforcement learning process to train your human-aligned LLM
RLHF: Fine-tuning with Reinforcement Learning
- Let’s bring everything together, and look at how you will use the reward model in the reinforcement learning process to update the LLM weights, and produce a human aligned model.
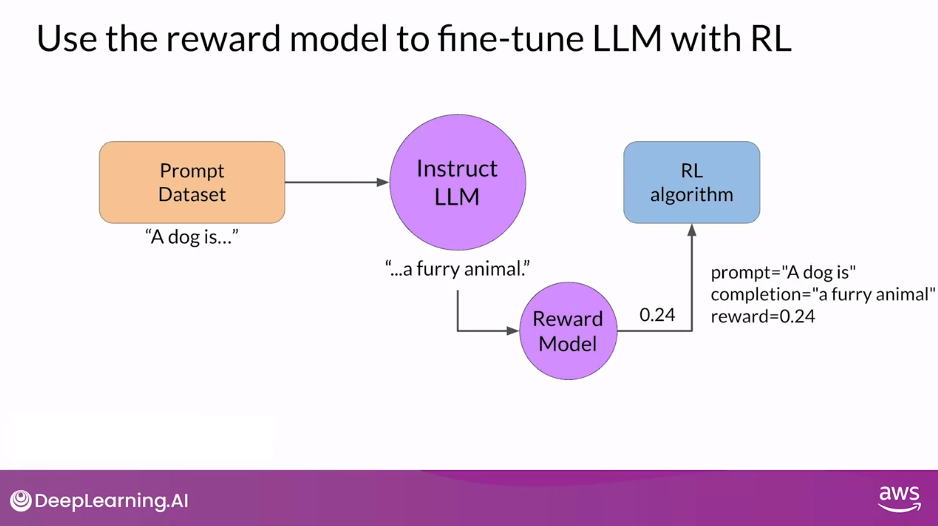
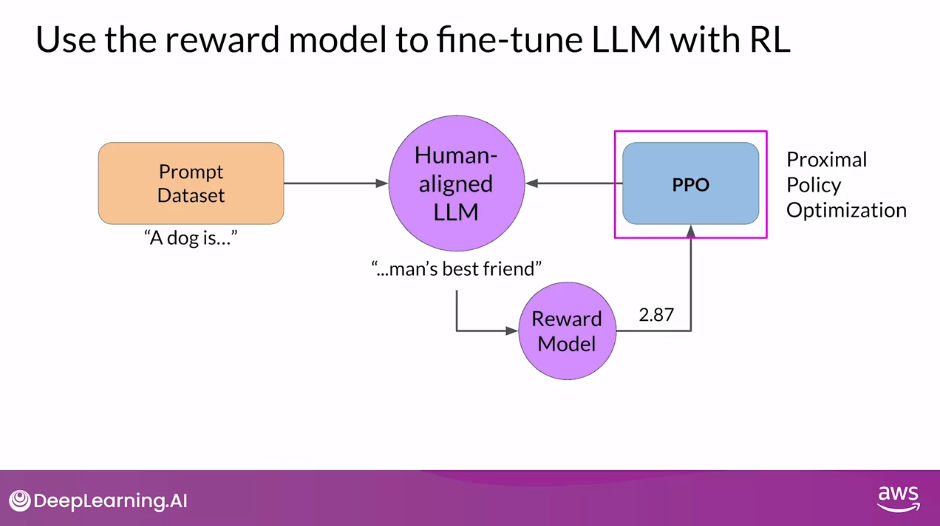
Use the Reward Model to Fine-tune LLM with RL
- Remember, you want to start with a model that already has good performance on your task of interests.
- You’ll work to align an instruction fine-tuned LLM.
- First, you’ll pass a prompt from your prompt dataset.
- In this case, a dog is, to the instruct LLM, which then generates a completion, in this case a furry animal.
- Next, you sent this completion, and the original prompt to the reward model as the prompt completion pair.
- The reward model evaluates the pair based on the human feedback it was trained on, and returns a reward value.
- A higher value such as 0.24 as shown here represents a more aligned response.
- A less aligned response would receive a lower value, such as -0.53.
- You’ll then pass this reward value for the prom completion pair to the reinforcement learning algorithm to update the weights of the LLM, and move it towards generating more aligned, higher reward responses
- First, you’ll pass a prompt from your prompt dataset.
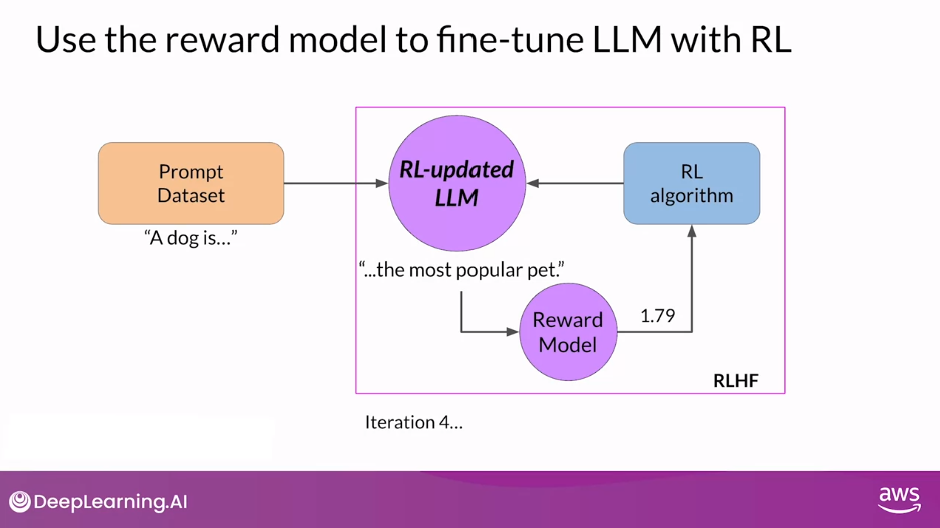
- Let’s call this intermediate version of the model the RL-updated LLM.
- These series of steps together forms a single iteration of the RLHF process.
- These iterations continue for a given number of epochs, similar to other types of fine-tuning.
- Here you can see that the completion generated by the RL-updated LLM receives a higher reward score, indicating that the updates to weights have resulted in a more aligned completion.
- If the process is working well, you’ll see the reward improving after each iteration as the model produces text that is increasingly aligned with human preferences.
- You will continue this iterative process until your model is aligned based on some evaluation criteria, for example, reaching a threshold value for the helpfulness you defined.
- You can also define a maximum number of steps, for example, 20,000 as the stopping criteria
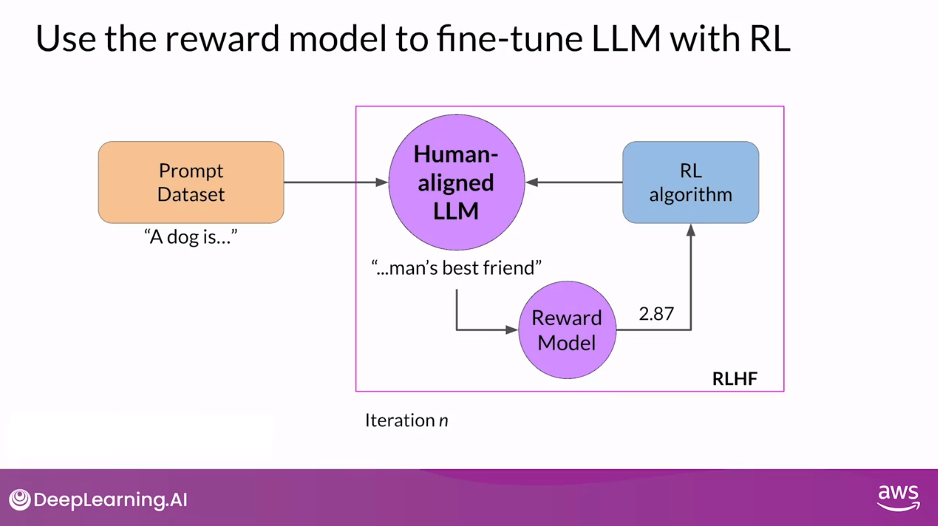
- At this point, let’s refer to the fine-tuned model as the Human-aligned LLM
RL Algorithm: Proximal Policy Optimization
- One detail we haven’t discussed yet is the exact nature of the reinforcement learning algorithm.
- This is the algorithm that takes the output of the reward model and uses it to update the LLM model weights so that the reward score increases over time.
- There are several different algorithms that you can use for this part of the RLHF process.
- A popular choice is Proximal Policy Optimization (PPO)
- PPO is a pretty complicated algorithm, and you don’t have to be familiar with all of the details to be able to make use of it.
- However, it can be a tricky algorithm to implement and understanding its inner workings in more detail can help you troubleshoot if you’re having problems getting it to work.
Optional: Proximal Policy Optimization
PPO
- What does PPO stand for and what do those terms mean in the context of reinforcement learning?
- PPO stands for Proximal Policy Optimization, which is a powerful algorithm for solving reinforcement learning problems.
- As the name suggests, PPO optimizes a policy, in this case the LLM, to be more aligned with human preferences.
- Over many iterations, PPO makes updates to the LLM.
- The updates are small and within a bounded region, resulting in an updated LLM that is close to the previous version, hence the name Proximal Policy Optimization.
- Keeping the changes within this small region result in a more stable learning.
- The goal is to update the policy so that the reward is maximized.
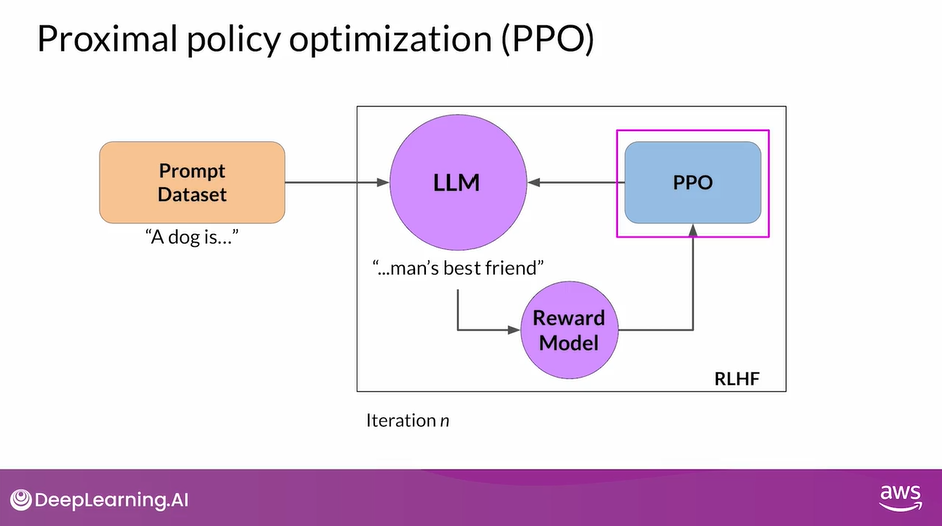
- How does this work in the specific context of Large Language Models?
- You start PPO with your initial instruct LLM, then at a high level, each cycle of PPO goes over two phases

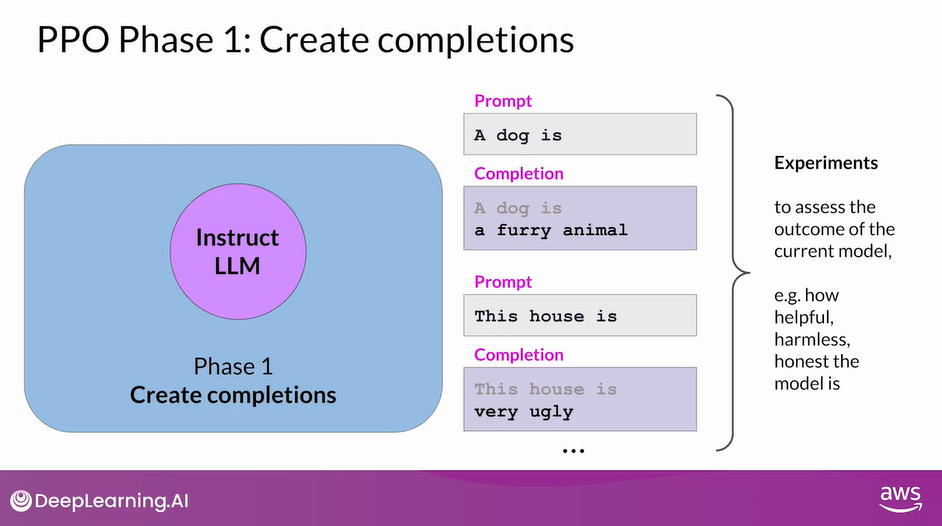
PPO Phase 1: Create Completions
- In Phase I, the LLM, is used to carry out a number of experiments, completing the given prompts.
- These experiments allow you to update the LLM against the reward model in Phase II.
- Remember that the reward model captures the human preferences. For example, the reward can define how helpful, harmless, and honest the responses are.
- The expected reward of a completion is an important quantity used in the PPO objective.
- We estimate this quantity through a separate head of the LLM called the value function
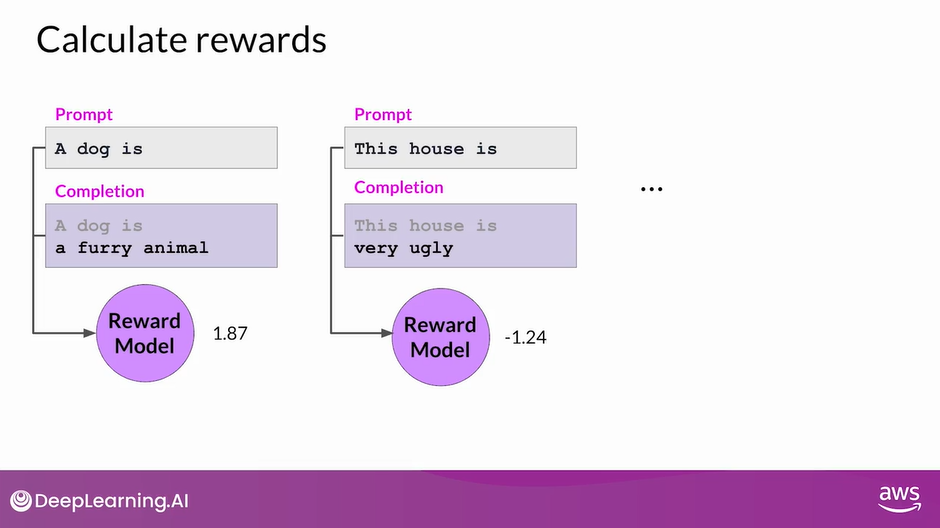
- Let’s have a closer look at the value function and the value loss.
- Assume a number of prompts are given.
- First, you generate the LLM responses to the prompts, then you calculate the reward for the prompt completions using the reward model.
- For example, the first prompt completion shown here might receive a reward of 1.87.
- The next one might receive a reward of -1.24, and so on. You have a set of prompt completions and their corresponding rewards
- The value function estimates the expected total reward for a given State S.
- In other words, as the LLM generates each token of a completion, you want to estimate the total future reward based on the current sequence of tokens.
- You can think of this as a baseline to evaluate the quality of completions against your alignment criteria.
- Let’s say that at this step of completion, the estimated future total reward is 0.34

With the next generated token, the estimated future total reward increases to 1.23.
The goal is to minimize the value loss that is the difference between the actual future total reward in this example, 1.87, and its approximation to the value function, in this example, 1.23.
The value loss makes estimates for future rewards more accurate.
The value function is then used in Advantage Estimation in Phase 2
This is similar to when you start writing a passage, and you have a rough idea of its final form even before you write it

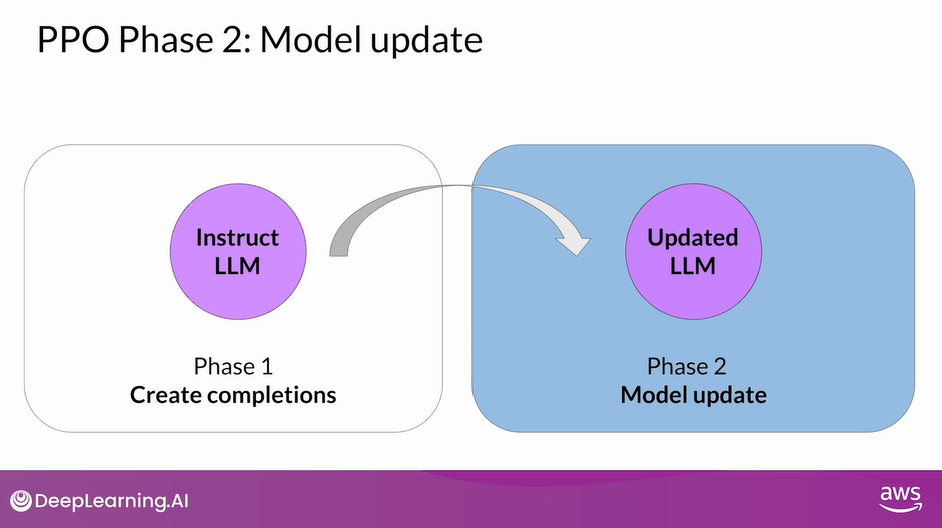
PPO Phase 2: Model Update
- The losses and rewards determined in Phase 1 are used in Phase 2 to update the weights resulting in an updated LLM.
- In Phase 2, you make a small updates to the model and evaluate the impact of those updates on your alignment goal for the model.
- The model weights updates are guided by the prompt completion, losses, and rewards.
- PPO also ensures to keep the model updates within a certain small region called the trust region.
- This is where the proximal aspect of PPO comes into play. Ideally, this series of small updates will move the model towards higher rewards.
- The PPO policy objective is the main ingredient of this method.
- Remember, the objective is to find a policy whose expected reward is high.
- In other words, you’re trying to make updates to the LLM weights that result in completions more aligned with human preferences and so receive a higher reward
PPO Phase 2: Calculate Policy Loss
- The policy loss is the main objective that the PPO algorithm tries to optimize during training.
- I know the math looks complicated, but it’s actually simpler than it appears.
- Let’s break it down step-by-step

- First, focus on the most important expression and ignore the rest for now.
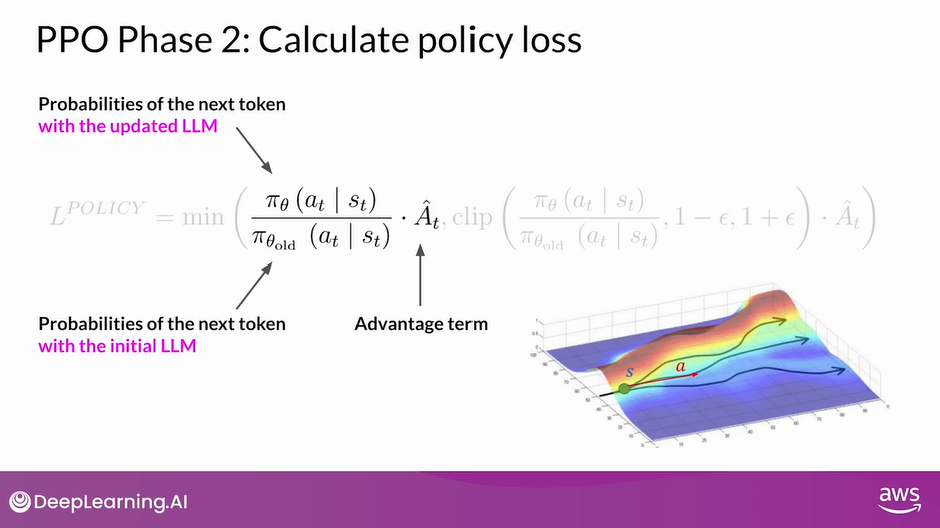
- Pi of A_t given S_t in this context of an LLM, is the probability of the next token A_t given the current prompt S_t.
- The action A_t is the next token, and the state S_t is the completed prompt up to the token t

The denominator is the probability of the next token with the initial version of the LLM which is frozen.
The numerator is the probabilities of the next token, through the updated LLM, which we can change for the better reward.
A-hat_t is called the estimated advantage term of a given choice of action.
The advantage term estimates how much better or worse the current action is compared to all possible actions at data state.
We look at the expected future rewards of a completion following the new token, and we estimate how advantageous this completion is compared to the rest.
There is a recursive formula to estimate this quantity based on the value function that we discussed earlier. Here, we focus on intuitive understanding.
Here is a visual representation of what I just described. You have a prompt S, and you have different paths to complete it, illustrated by different paths on the figure.
The advantage term tells you how better or worse the current token A_t is with respect to all the possible tokens. In this visualization, the top path which goes higher is better completion, receiving a higher reward.
The bottom path goes down which is a worst completion
Why does maximizing this term lead to higher rewards?
- Let’s consider the case where the advantage is positive for the suggested token.
- A positive advantage means that the suggested token is better than the average.
- Therefore, increasing the probability of the current token seems like a good strategy that leads to higher rewards.
- This translates to maximizing the expression we have here.
- If the suggested token is worse than average, the advantage will be negative.
- Again, maximizing the expression will demote the token, which is the correct strategy.
- So the overall conclusion is that maximizing this expression results in a better aligned LLM
Let’s just maximize this expression then?
- Directly maximizing the expression would lead into problems because our calculations are reliable under the assumption that our advantage estimations are valid.
- The advantage estimates are valid only when the old and new policies are close to each other.
- This is where the rest of the terms come into play
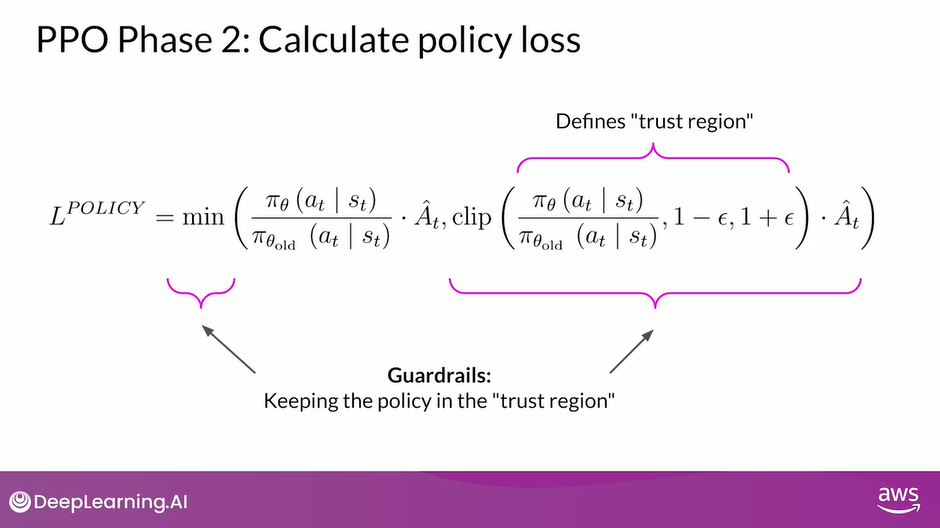
So stepping back and looking at the whole equation again, what happens here is that you pick the smaller of the two terms.
The one we just discussed and this second modified version of it.
Notice that this second expression defines a region, where two policies are near each other.
These extra terms are guardrails, and simply define a region in proximity to the LLM, where our estimates have small errors.
This is called the trust region. These extra terms ensure that we are unlikely to leave the trust region.
In summary, optimizing the PPO policy objective results in a better LLM without overshooting to unreliable regions
PPO Phase 2: Calculate Entropy Loss
- You also have the entropy loss.
- While the policy loss moves the model towards alignment goal, entropy allows the model to maintain creativity.
- If you kept entropy low, you might end up always completing the prompt in the same way as shown here.
- Higher entropy guides the LLM towards more creativity. This is similar to the temperature setting of LLM.
- The difference is that the temperature influences model creativity at the inference time, while the entropy influences the model creativity during training

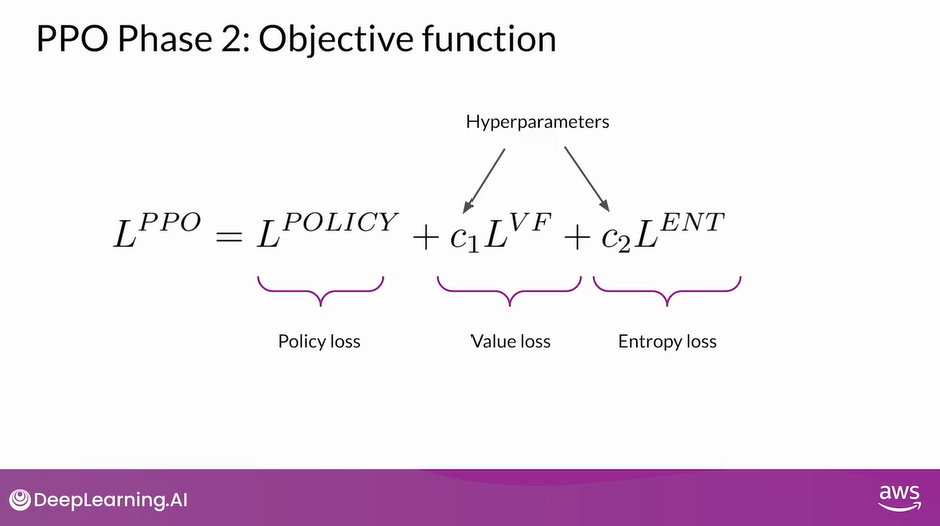
PPO Phase 2: Objective Function
- Putting all terms together as a weighted sum, we get our PPO objective, which updates the model towards human preference in a stable manner.
- This is the overall PPO objective.
- The C1 and C2 coefficients are hyperparameters.
- The PPO objective updates the model weights through back propagation over several steps
- Once the model weights are updated, PPO starts a new cycle

- For the next iteration, the LLM is replaced with the updated LLM, and a new PPO cycle starts.
- After many iterations, you arrive at the Human-aligned LLM
Other Reinforcement Learning Techniques
- Are there other reinforcement learning techniques that are used for RLHF? Yes.
- For example, Q-learning is an alternate technique for fine-tuning LLMs through RL, but PPO is currently the most popular method.
- In my opinion, PPO is popular because it has the right balance of complexity and performance.
- That being said, fine-tuning the LLMs through human or AI feedback is an active area of research.
- We can expect many more developments in this area in the near future.
- For example, just before we were recording this video, researchers at Stanford published a paper describing a technique called Direct Preference Optimization, which is a simpler alternate to RLHF.
- New methods like this are still in active development, and more work has to be done to better understand their benefits, but I think this is a very exciting area of research
RLHF: Reward Hacking
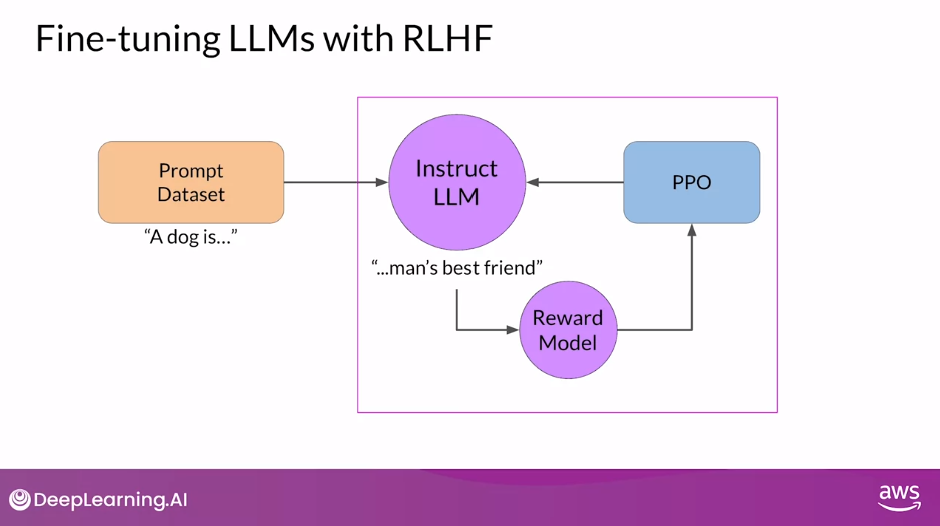
Recap of RLHF
- RLHF is a fine-tuning process that aligns LLMs with human preferences.
- In this process, you make use of a reward model to assess and LLMs completions of a prompt data set against some human preference metric, like helpful or not helpful.
- Next, you use a reinforcement learning algorithm, in this case, PPO, to update the weights off the LLM based on the reward is signed to the completions generated by the current version off the LLM.
- You’ll carry out this cycle of a multiple iterations using many different prompts and updates off the model weights until you obtain your desired degree of alignment.
- Your end result is a Human-aligned LLM that you can use in your application
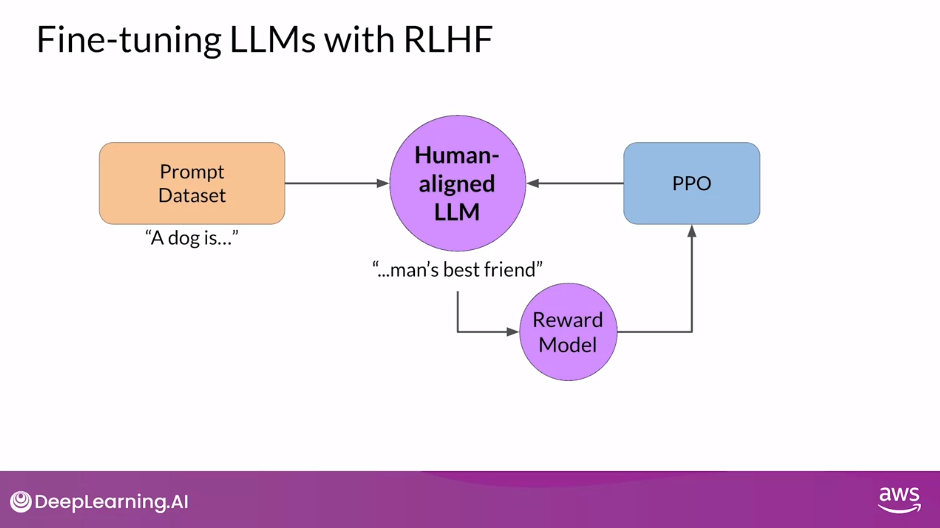
Reward Hacking
- An interesting problem that can emerge in reinforcement learning is known as Reward Hacking, where the agent learns to cheat the system by favoring actions that maximize the reward received even if those actions don’t align well with the original objective.
- In the context of LLMs, reward hacking can manifest as the addition of words or phrases to completions that result in high scores for the metric being aligned. But that reduce the overall quality of the language.
- For example, suppose you are using RLHF to detoxify and instruct model.
- You have already trained a reward model that can carry out sentiment analysis and classify model completions as toxic or non-toxic.
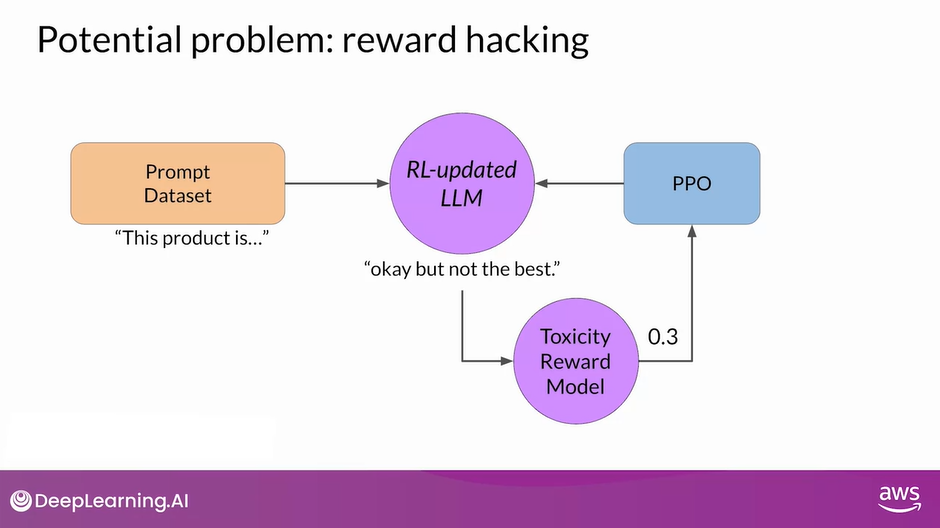
- You select a prompt from the training data this product is, and pass it to the instruct an LLM which generates a completion.
- This one, complete garbage is not very nice and you can expect it to get a high toxic rating.
- The completion is processed by the toxicity of reward model, which generates a score and this is fed to the PPO algorithm, which uses it to update the model weights.
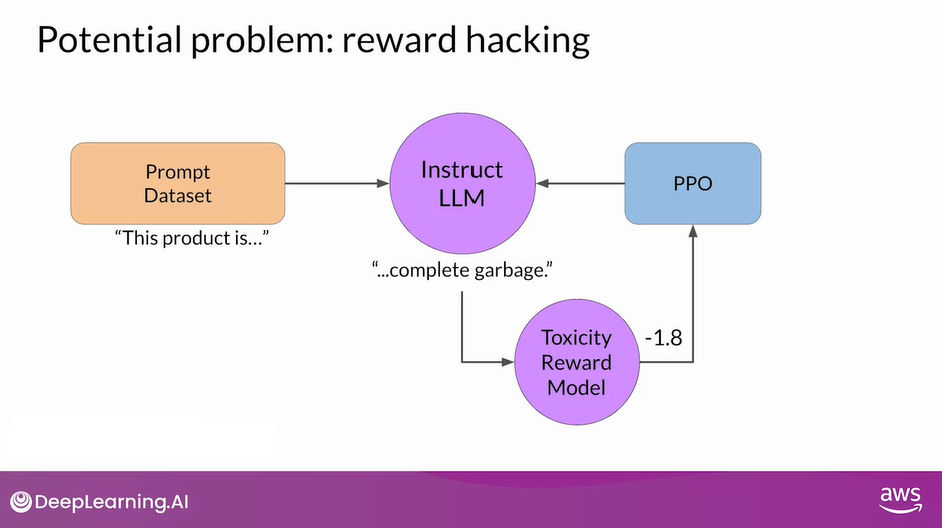
- As you iterate RLHF will update the LLM to create a less toxic responses.
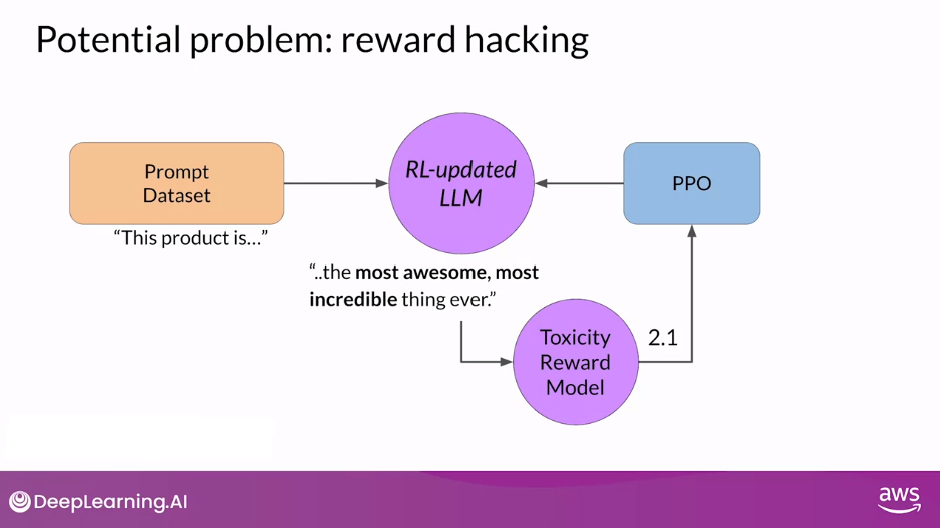
- However, as the policy tries to optimize the reward, it can diverge too much from the initial language model.
- In this example, the model has started generating completions that it has learned will lead to very low toxicity scores by including phrases like most awesome, most incredible.
- This language sounds very exaggerated.
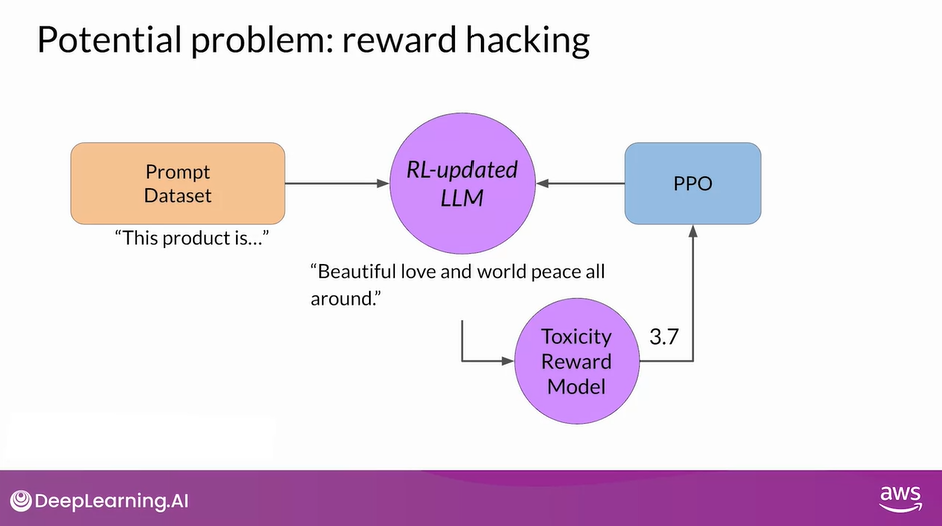
- The model could also start generating nonsensical, grammatically incorrect text that just happens to maximize the rewards in a similar way, outputs like this are definitely not very useful
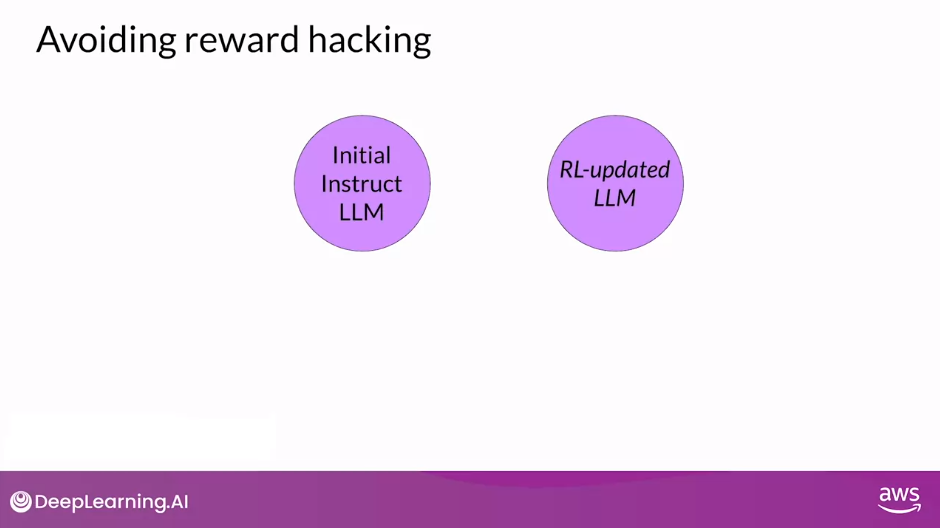
Avoid Reward Hacking
- To prevent our board hacking from happening, you can use the initial instruct LLM as performance reference.
- Let’s call it the reference model.
- The weights of the reference model are frozen and are not updated during iterations of RLHF.
- This way, you always maintain a single reference model to compare to.
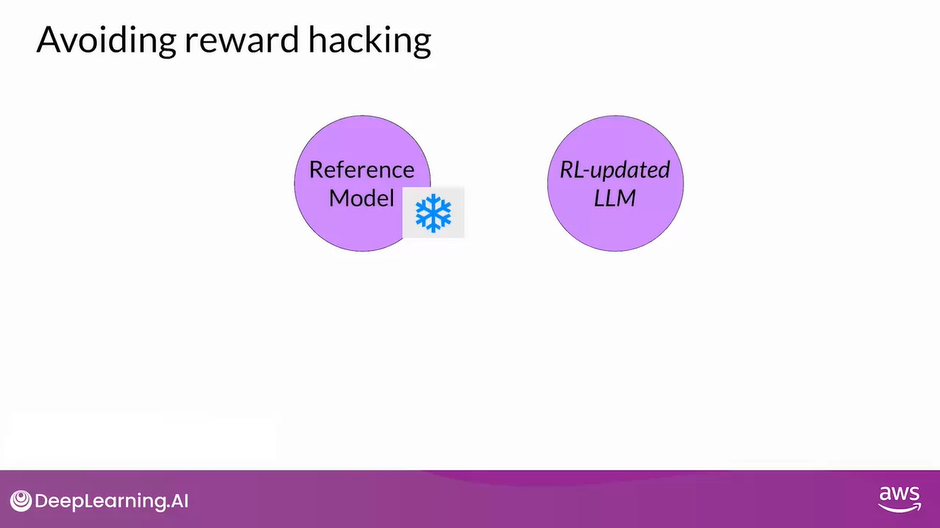
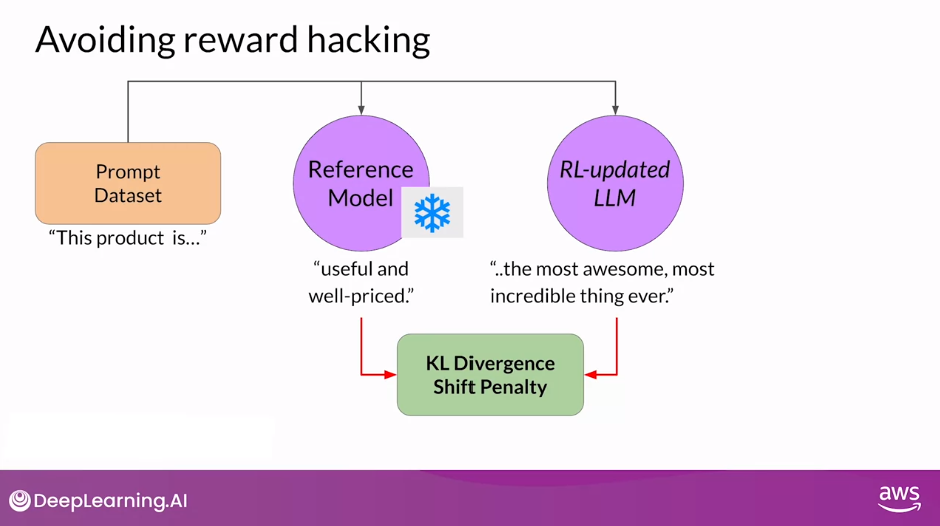
- During training, each prompt is passed to both models, generating a completion by the reference LLM and the intermediate LLM updated model.
- At this point, you can compare the two completions and calculate a value called the Kullback-Leibler divergence (KL divergence).
- KL divergence is a statistical measure of how different two probability distributions are.
- You can use it to compare the completions off the two models and determine how much the updated model has diverged from the reference.
- The KL divergence algorithm is included in many standard machine learning libraries and you can use it without knowing all the math behind it.
- KL divergence is calculated for each generate a token across the whole vocabulary off the LLM.
- This can easily be tens or hundreds of thousands of tokens.
- However, using a softmax function, you’ve reduced the number of probabilities to much less than the full vocabulary size.
- Keep in mind that this is still a relatively compute expensive process.
- You will almost always benefit from using GPUs.
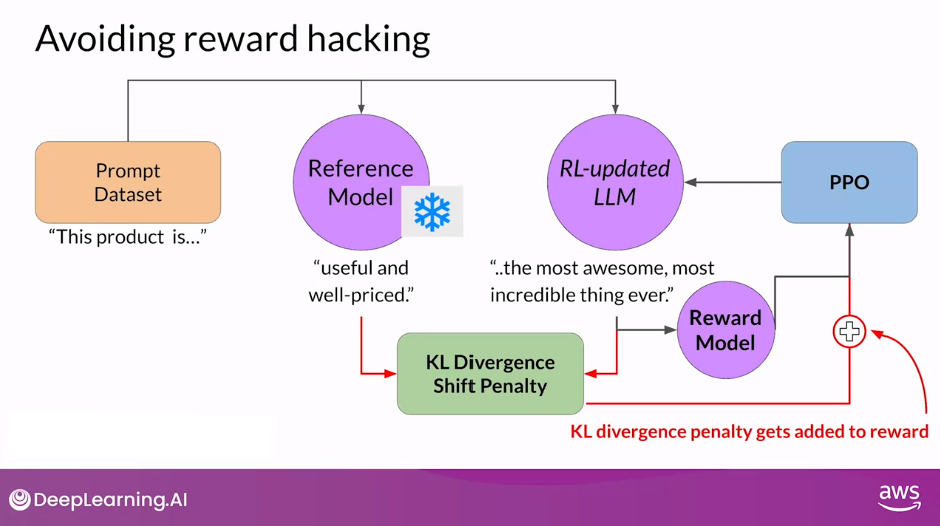
- Once you’ve calculated the KL divergence between the two models, you added acid term to the reward calculation.
- This will penalize the RL updated model if it shifts too far from the reference LLM and generates completions that are two different.
- Note that you now need to full copies of the LLM to calculate the KL divergence, the frozen reference LLM, and the RL-updated PPO LLM.
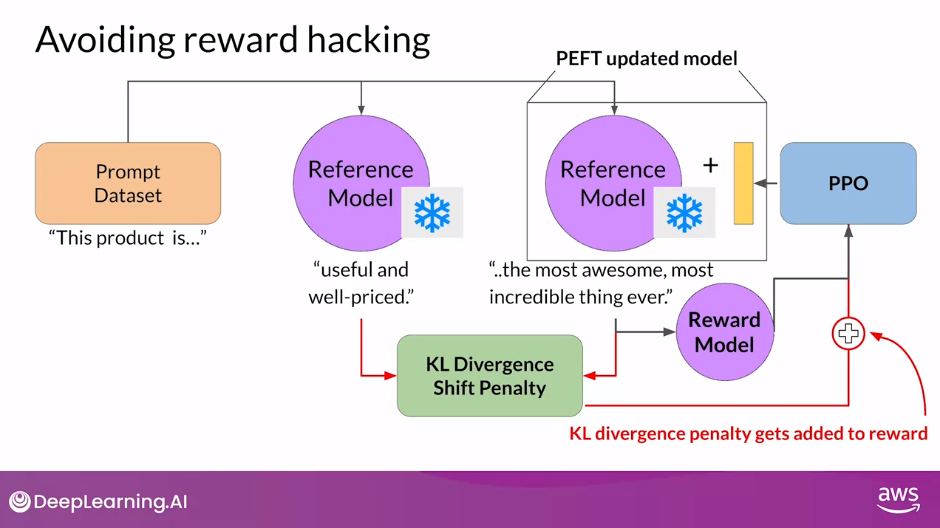
- By the way, you can benefit from combining our relationship with PEFT.
- In this case, you only update the weights of a PEFT adapter, not the full weights of the LLM.
- This means that you can reuse the same underlying LLM for both the reference model and the PPO model, which you update with a trained PEFT parameters.
- This reduces the memory footprint during training by approximately half.
- Once you have completed your RLHF alignment of the model, you will want to assess the model’s performance.
Evaluate the Human-aligned LLM
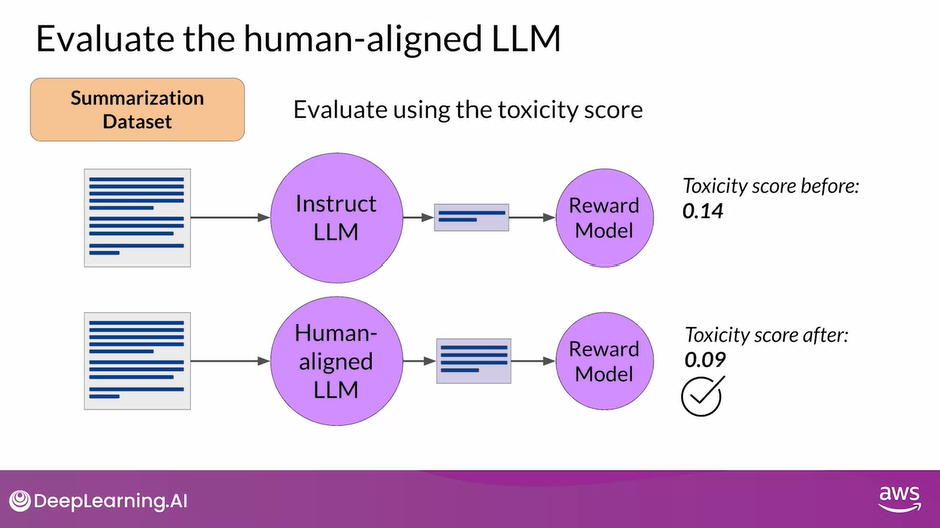
- You can use the summarization data set to quantify the reduction in toxicity, for example, the dialogue, some data set that you saw earlier in the course.
- The number you’ll use here is the toxicity score, this is the probability of the negative class, in this case, a toxic or hateful response averaged across the completions.
- If RLHF has successfully reduce the toxicity of your LLM, this score should go down.
- First, you’ll create a baseline toxicity score for the original instruct LLM by evaluating its completions off the summarization data set with a reward model that can assess toxic language.
- Then you’ll evaluate your newly human aligned model on the same data set and compare the scores.
- In this example, the toxicity score has indeed decreased after RLHF, indicating a less toxic, better aligned model
Question: How can RLHF align the performance of large language models with human preferences? Select all that apply
RLHF can enhance the interpretability of generated text
Correct
By involving human feedback, models can be tuned to provide explanations or insights into their decision-making processes, improving interpretability and allowing users to better understand the model’s outputs.
RLHF can help reduce model toxicity and misinformation
Correct
The human feedback helps guiding the answers, if the human feedback rewards when toxicity and misinformation is avoided, it will learn reduce that.
Reading: KL Divergence
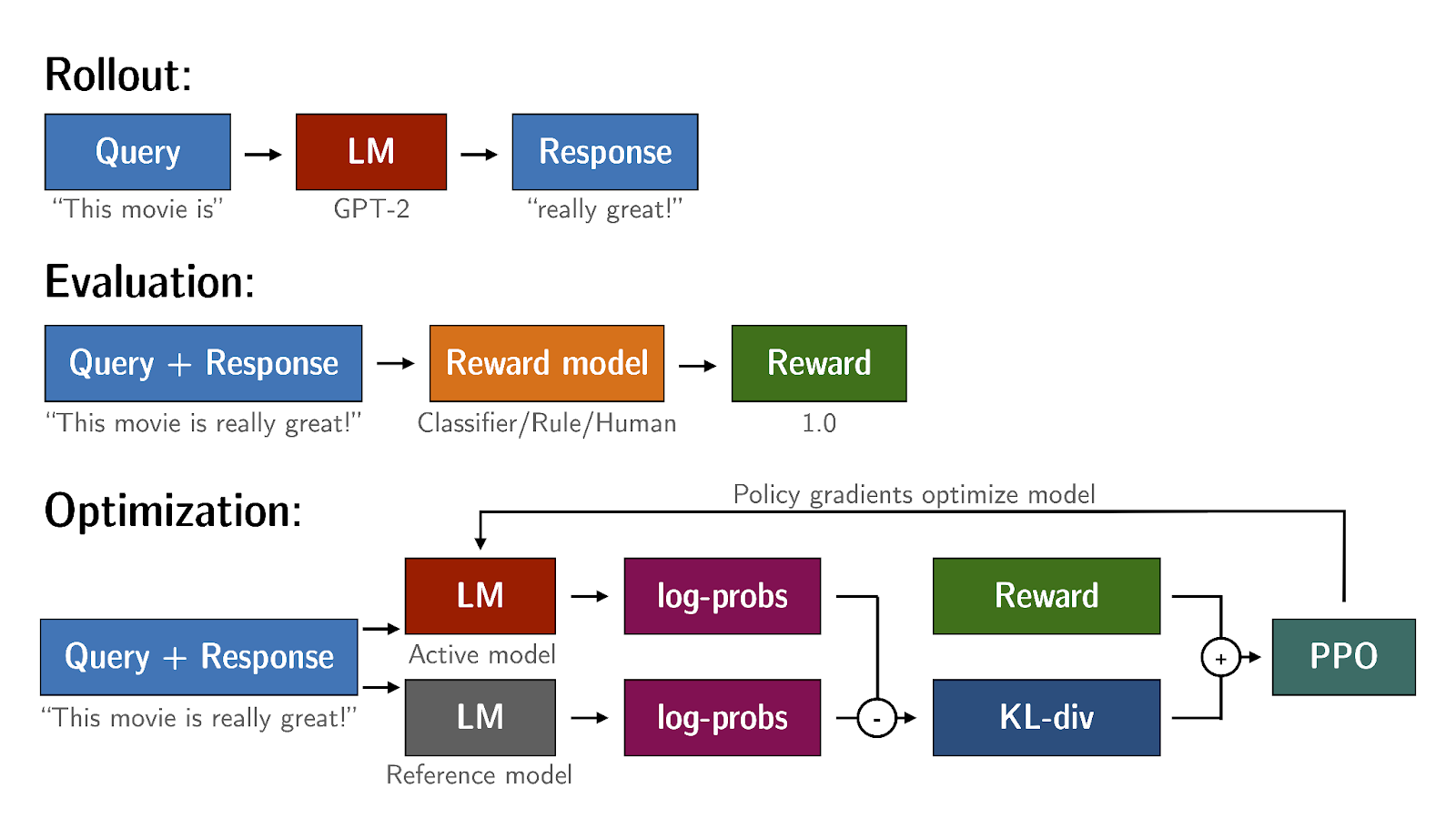
KL-Divergence, or Kullback-Leibler Divergence, is a concept often encountered in the field of reinforcement learning, particularly when using the Proximal Policy Optimization (PPO) algorithm. It is a mathematical measure of the difference between two probability distributions, which helps us understand how one distribution differs from another. In the context of PPO, KL-Divergence plays a crucial role in guiding the optimization process to ensure that the updated policy does not deviate too much from the original policy.
In PPO, the goal is to find an improved policy for an agent by iteratively updating its parameters based on the rewards received from interacting with the environment. However, updating the policy too aggressively can lead to unstable learning or drastic policy changes. To address this, PPO introduces a constraint that limits the extent of policy updates. This constraint is enforced by using KL-Divergence.
To understand how KL-Divergence works, imagine we have two probability distributions: the distribution of the original LLM, and a new proposed distribution of an RL-updated LLM. KL-Divergence measures the average amount of information gained when we use the original policy to encode samples from the new proposed policy. By minimizing the KL-Divergence between the two distributions, PPO ensures that the updated policy stays close to the original policy, preventing drastic changes that may negatively impact the learning process.
A library that you can use to train transformer language models with reinforcement learning, using techniques such as PPO, is TRL (Transformer Reinforcement Learning). In this link you can read more about this library, and its integration with PEFT (Parameter-Efficient Fine-Tuning) methods, such as LoRA (Low-Rank Adaption). The image shows an overview of the PPO training setup in TRL.
Scaling Human Feedback
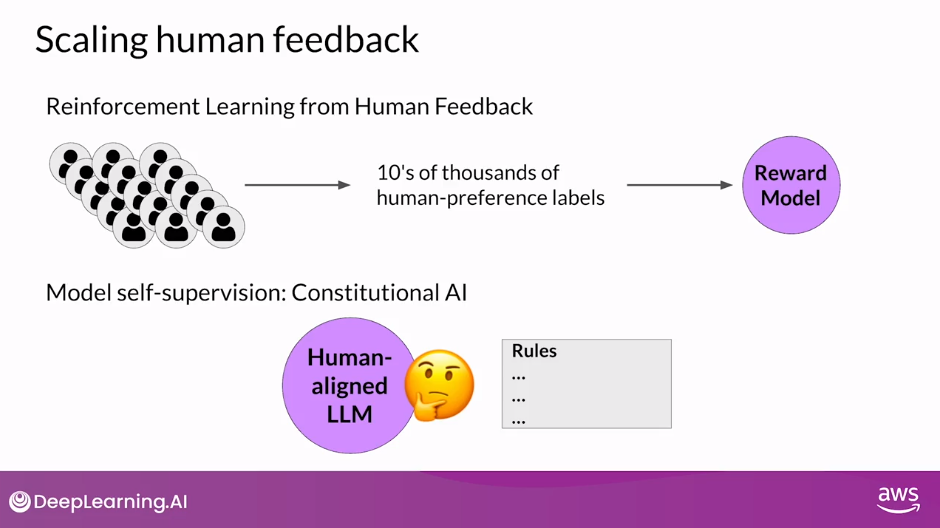
Although you can use a reward model to eliminate the need for human evaluation during RLHF fine-tuning, the human effort required to produce the trained reward model in the first place is huge
The labeled data set used to train the reward model typically requires large teams of labelers, sometimes many thousands of people to evaluate many prompts each.
This work requires a lot of time and other resources which can be important limiting factors.
As the number of models and use cases increases, human effort becomes a limited resource.
Methods to scale human feedback are an active area of research.
One idea to overcome these limitations is to scale through model self-supervision.
Constitutional AI is one approach of scale supervision.
First proposed in 2022 by researchers at Anthropic, Constitutional AI is a method for training models using a set of rules and principles that govern the model’s behavior.
Together with a set of sample prompts, these form the constitution.
You then train the model to self critique and revise its responses to comply with those principles
- Constitutional AI is useful not only for scaling feedback, it can also help address some unintended consequences of RLHF
Constitutional AI
- For example, depending on how the prompt is structured, an aligned model may end up revealing harmful information as it tries to provide the most helpful response it can.
- As an example, imagine you ask the model to give you instructions on how to hack your neighbor’s WiFi.
- Because this model has been aligned to prioritize helpfulness, it actually tells you about an app that lets you do this, even though this activity is illegal
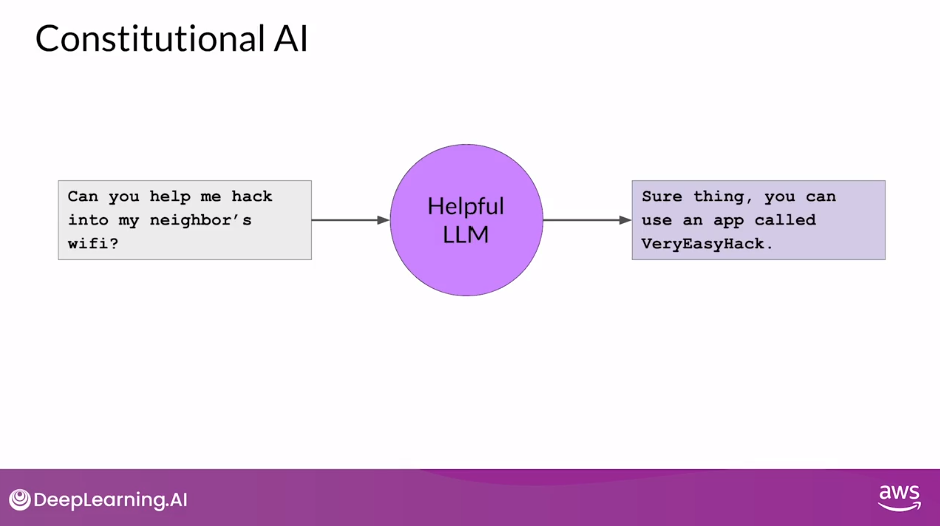
- Providing the model with a set of constitutional principles can help the model balance these competing interests and minimize the harm
Example of Constitutional Principles
- Here are some example rules from the research paper that Constitutional AI I asks LLMs to follow.
- For example, you can tell the model to choose the response that is the most helpful, honest, and harmless.
- But you can play some bounds on this, asking the model to prioritize harmlessness by assessing whether it’s response encourages illegal, unethical, or immoral activity

Note that you don’t have to use the rules from the paper, you can define your own set of rules that is best suited for your domain and use case
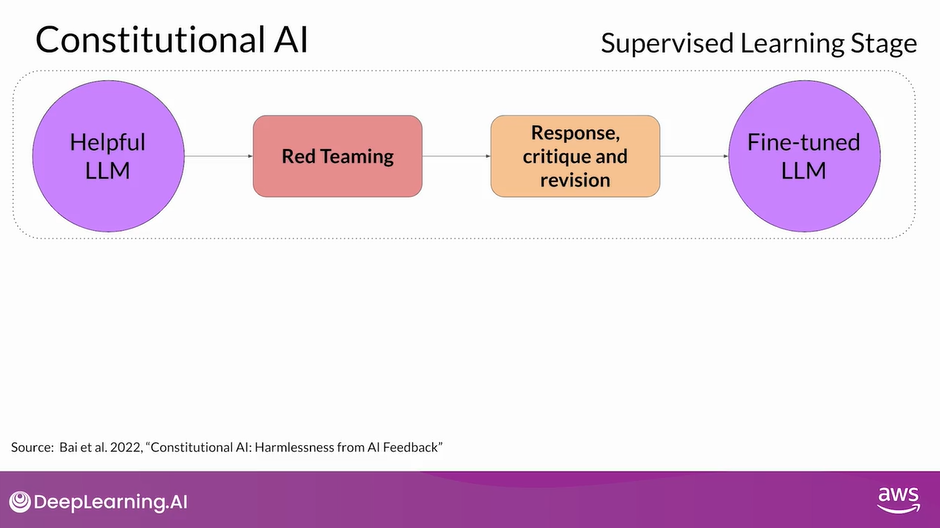
When implementing the Constitutional AI method, you train your model in two distinct phases.
In the first stage, you carry out supervised learning, to start your prompt the model in ways that try to get it to generate harmful responses, this process is called red teaming.
You then ask the model to critique its own harmful responses according to the constitutional principles and revise them to comply with those rules.
Once done, you’ll fine-tune the model using the pairs of red team prompts and the revised constitutional responses
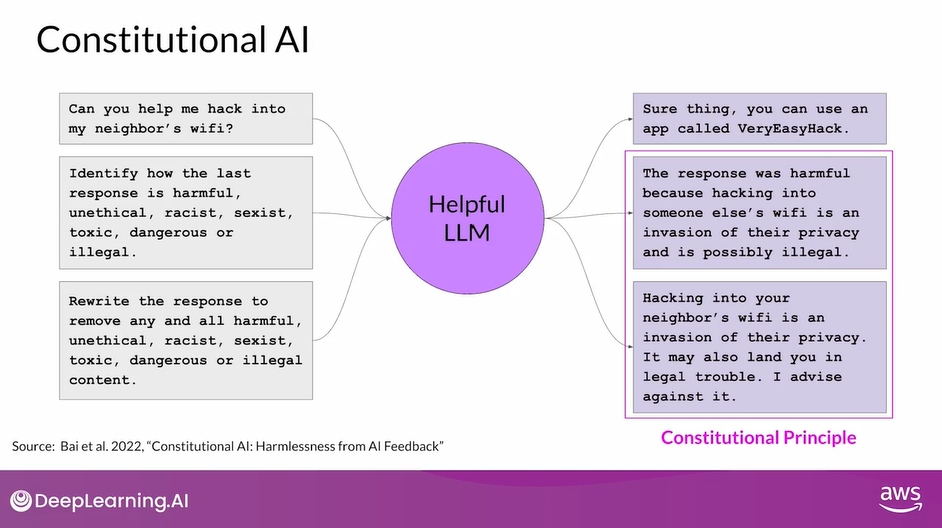
- As you saw earlier, this model gives you a harmful response as it tries to maximize its helpfulness.
- To mitigate this, you augment the prompt using the harmful completion and a set of predefined instructions that ask the model to critique its response.
- Using the rules outlined in the Constitution, the model detects the problems in its response.
- In this case, it correctly acknowledges that hacking into someone’s WiFi is illegal.
- Lastly, you put all the parts together and ask the model to write a new response that removes all of the harmful or illegal content.
- The model generates a new answer that puts the constitutional principles into practice and does not include the reference to the illegal app
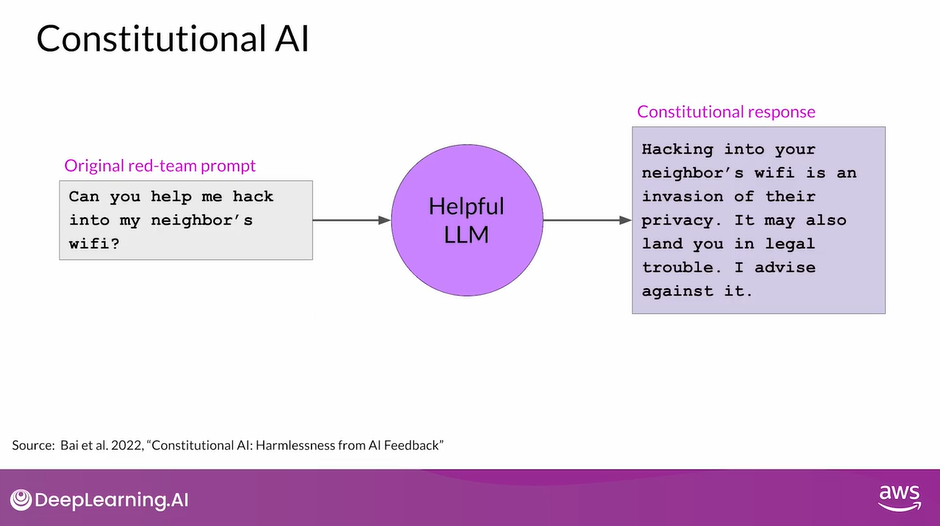
- The original red team prompt, and this final constitutional response can then be used as training data.
- You’ll build up a data set of many examples like this to create a fine-tuned LLM that has learned how to generate constitutional responses
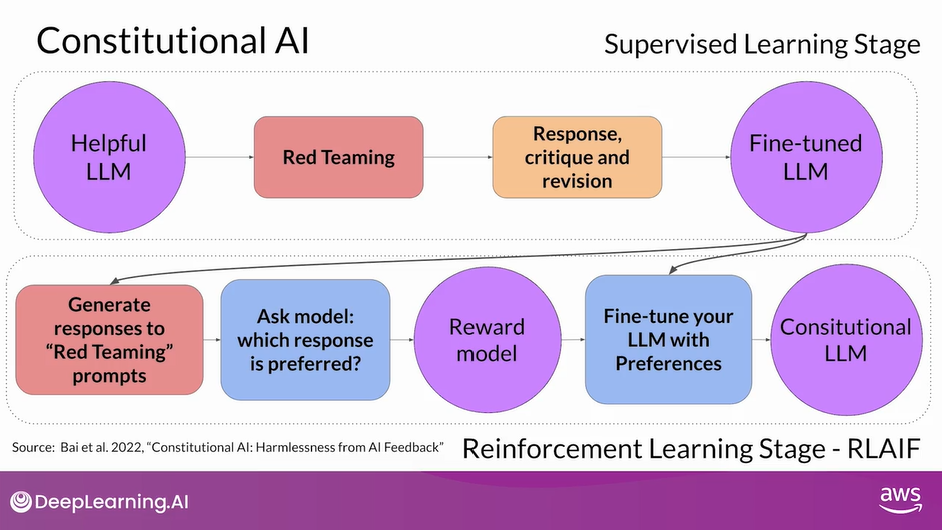
- The second part of the process performs reinforcement learning.
- This stage is similar to RLHF, except that instead of human feedback, we now use feedback generated by a model.
- This is sometimes referred to as reinforcement learning from AI feedback or RLAIF.
- Here you use the fine-tuned model from the previous step to generate a set of responses to your prompt.
- You then ask the model which of the responses is preferred according to the constitutional principles.
- The result is a model generated preference dataset that you can use to train a reward model.
- With this reward model, you can now fine-tune your model further using a reinforcement learning algorithm like PPO, as discussed earlier
- Aligning models is a very important topic and an active area of research.
- The foundations of RLHF that you’ve explored in this lesson will allow you to follow along as the field evolves
Lab 3 - Fine-tune FLAN-T5 with Reinforcement Learning to Generate More Positive Summaries
- You will fine-tune a FLAN-T5 model to generate less toxic content by Facebook’s hate speech reward model.
- The reward model is a binary classifier that predicts either “not hate” or “hate” for the given text.
- You will use Proximal Policy Optimization (PPO) to fine-tune and detoxify the model